GPU on Bare Metal Servers
Read about GPU on Bare Metal servers. Understand why this is an ideal configuration for AI, ML, and data-intensive workloads that demand low latency, hardware-level control, and consistent high-throughput.

These days, I am witnessing businesses increasingly returning to bare metal infrastructure after years dominated by virtualization and cloud solutions.
But what is driving this renewed interest in bare metal servers?
In my opinion, the raw, uncompromised performance, zero virtualization overhead, and direct hardware access are just a few reasons behind this shift.
In the case of businesses running AI/ML pipelines, the cloud’s abstraction layers can hinder the GPU utilization in scenarios when you don’t have a millisecond to waste.
In this article, we will help you understand the idea of GPU on bare metal servers, deployment models, whether your use case truly demands one, and if so, how to choose the right one.
Let’s start with a brief overview of GPU bare metal servers.
What is a GPU Bare Metal Server?
A GPU (graphics processing unit) bare metal server is a physical server that provides direct access to GPU hardware without any virtualization layer in between. As someone who works with these systems daily, I see GPU bare metal servers provide:
- Seamless access to GPU hardware
- No virtualization overheads
- Complete control over GPU configurations and drivers
- Improved security
- Exceptional support for computationally-intensive tasks
As someone who has hands-on experience with both traditional cloud servers and bare metal servers, I’ve observed cloud servers use virtualization to share resources among multiple users, which impacts performance in the case of AI and ML tasks. With bare metal servers, you get unvirtualized access to physical GPU hardware, offering maximum performance.
From users’ point of view, the option to choose the GPU is the best feature of the GPU bare metal servers.
Key Components of a Bare Metal GPU Server
A typical bare metal GPU server has the following two key components:
Bare Metal Infrastructure
The foundation of a bare metal GPU server is the bare metal infrastructure itself, which makes high-performance GPU computing possible.
A bare metal server is usually allocated to a single user and is not shared with other tenants. As such, you have full control and isolation. There are no hypervisors or virtualization layers, giving you predictable performance and security.
A typical bare metal infrastructure includes:
- Physical dedicated server hardware
- Complete tenant isolation for security
- Direct access to system resources
- The option to customizable operating system and drivers
GPU Hardware
Now, let’s talk about the GPUs themselves. With the adoption of AI, ML, and deep learning, large datasets need to be handled, creating a high demand for GPUs.
I would always recommend that my users understand their use case and select the GPU family accordingly. For instance, if your workload involves AI training and inference, ultra-large-scale AI models, NVIDIA’s data center GPUs like the H100 PCIe, H100 NVL, and A100 (80GB) PCIe would be suitable.
When selecting a GPU, look for workload type, memory capacity, power efficiency, and scalability.
Cloud GPUs vs Bare Metal GPUs
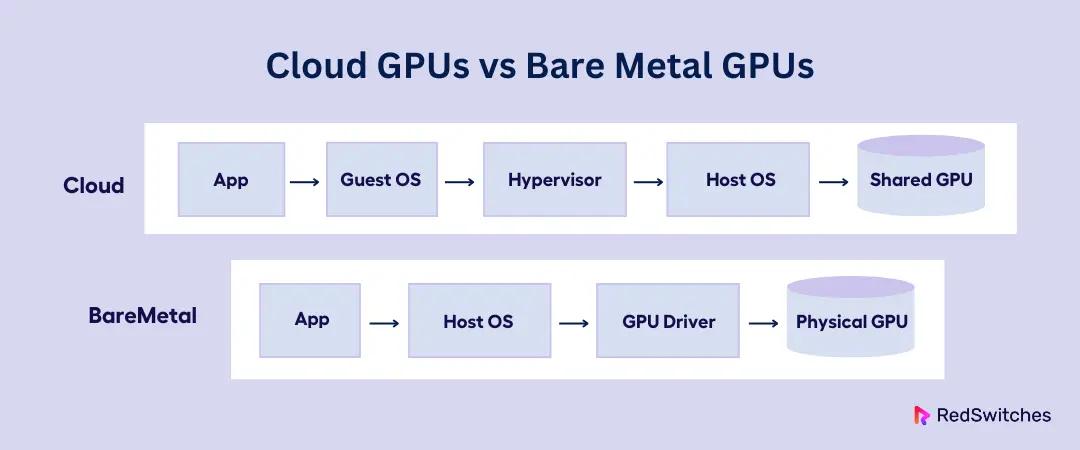
Like I said, there is an ongoing trend of shifting from cloud GPUs to bare metal GPUs. However, changing your infrastructure is not about going with the trend; it’s about understanding your needs and choosing the right strategy. Here is an overview of the cloud and bare metal GPU infrastructures to help you choose the right option for your project specifications.
Cloud GPU Overview
Cloud GPU services are offered by providers like AWS, GCP, and Azure. They allow users to achieve cost-efficient resource sharing with multiple tenants.
The cloud GPUs offer the following:
- Shared infrastructure for cost optimization
- Flexible scaling capabilities
- Pay-as-you-go pricing model
- Integration with cloud services
Bare Metal GPU Overview
With bare metal, you rent or own dedicated physical servers with GPU hardware. What makes people choose bare metal GPUs over cloud GPUs is their high performance, security, and customization. They provide:
- Consistent, predictable performance
- Complete hardware control
- Enhanced security through physical isolation
- Regulatory compliance capabilities
| Cloud GPU Versus Bare Metal GPU | ||
|---|---|---|
| Feature | Cloud GPUs | Bare Metal GPUs |
| Latency | Higher due to virtualization and multi-tenant setup. | Lower, as resources are dedicated and directly accessible. |
| Customization | Limited, depends on the provider’s options and APIs. | Full hardware and software customization. |
| Pricing | Pay-as-you-go, scalable, but can be costly for consistent use over time. | Higher initial investment, but potentially cheaper long-term for steady workloads. |
| SLAs & Support | Managed by cloud provider, variable depending on plan. | Fully under your control, can tailor SLAs; supports more rigorous SLAs. |
| Elasticity | High elasticity allows scaling resources up or down with ease. | Low elasticity requires manual scaling or additional hardware. |
| Security and Compliance | Shared infrastructure, more concerns of isolation. | Complete control, better suited for sensitive data. |
| Control | Full hardware and software control | Limited control over underlying hardware |
Bare Metal GPU Deployment Models
In my years of experience, one key aspect I have noticed is how deployment models are underestimated. In fact, the deployment models are as important as GPU hardware specifications.
The two primary bare metal GPU dedicated models are:
- Dedicated Bare Metal
- Managed Bare Metal
Let’s discuss these models.
Dedicated Bare Metal
When I work with organizations that have experienced internal IT teams or specific performance or compliance requirements, I often recommend dedicated bare metal. This model gives complete control over the hardware and resources and you can configure, optimize, and use the GPU and server resources as needed by the project.
The key advantages of the dedicated bare metal GPU model include:
- Customization of software stack and hardware settings
- No resource sharing with other tenants, ensuring predictable performance
- Ideal for specialized workloads, custom environments, or sensitive data processing operations
However, as a trade-off, you need to have a dedicated IT team for OS patching, driver updates, hardware monitoring, and troubleshooting any issues that arise.
Managed Bare Metal
For organizations that want bare-metal GPU performance without operational overhead, I frequently recommend managed bare-metal GPU services.
Here, the server is maintained by the vendor or service provider. They handle deployment, updates, and patch installation, and often take care of hardware maintenance.
The key advantages of the managed bare metal GPU model include:
- Reduced administrative overhead where you can focus on your workloads and don’t worry about infrastructure management
- Faster deployment times since provisioning is streamlined
- Consistent updates and security patches managed by the provider
Why Choose Bare Metal GPUs?
When working with clients with GPU-focused workloads, I often get the question: why choose bare metal GPUs?
The answer is not just about raw performance. It is about understanding the features it offers and how it aligns with your specific business and technical requirements.
Dedicated Performance
When you work with bare metal, you get full access to the GPU resources without any limitations. In practical terms, this means:
- Direct hardware access eliminates virtualization overhead
- Consistent, predictable performance for demanding workloads
- Maximum GPU utilization without resource contention
- Superior processing power compared to virtualized solutions
Scalability
Another important reason for choosing bare metal GPUs is scalability. You get the flexibility to increase or reduce GPU resources within the same bare metal server environment. Though cloud servers can scale, for long-term, resource-intensive workloads bare metal GPUs are ideal because of lower operational costs and faster response to load management requirements.
- The bare metal infrastructure supports various multi-GPU setup configurations within a single architecture
- High-speed GPU-to-GPU communication through NVIDIA NVLink, Infinity Fabric, or similar technologies
- Ability to create large GPU clusters connected via high-speed networks
- Dynamic workload distribution based on GPU utilization
Security and Isolation
When my clients have to choose between bare metal GPUs and cloud GPUs, security and isolation are often the two basic aspects that finalize the choice.
Since the hardware is exclusive to the user, the underlying software and user-defined processes and data remain safe and sandboxed because:
- There is complete physical isolation of hardware resources
- Enhanced data protection through hardware-level encryption
- Support for TPM and secure boot processes
- Comprehensive RBAC and MFA capabilities
This reduces potential vulnerabilities and helps users meet strict compliance standards.
Long-Term Cost Optimization
While the initial investment might be higher, in the long run, bare metal GPU solutions can offer better ROI, especially for sustained, high-load operations. For workloads that maintain high GPU utilization, you will see significant savings (up to 60 percent in some cases), when compared to cloud GPUs.
With bare metal, you’re not paying for unused capacity or dealing with the cost unpredictability that can come with cloud resource pricing changes.
Use Cases for Bare Metal GPUs
The following are some of the use cases of bare metal GPUs where their features and capabilities are a good fit for solving specific issues.
Large-Scale AI Model Training
Bare metal GPUs are appropriate for large-scale AI modelling for the following reasons:
- Training large language models requiring massive computational power
- Image recognition and computer vision model development
- Multi-GPU training for faster iteration cycles
- Ensures bandwidth, memory, and compute power required
Inference at Scale
Inference workloads often are the prime candidates for bare metal infrastructure.
Deploying AI models in production requires high throughput and low latency. Bare metal GPUs are ideal due to:
- High-throughput API services for real-time inference
- Low-latency transformer model serving
- Consistent performance for production workloads
Financial Modeling
The financial services industry has provided some interesting bare metal GPU implementation use cases, including:
- Real-time fraud detection systems
- High-frequency trading platforms
- Complex portfolio risk analysis
- Market simulation models
Graphics Rendering
Animation studios and visual effects companies depend on bare metal GPU deployments because of their performance and stability. The huge scale of movie-length digital media requires bare metal GPUs for rendering large scenes, complex simulations, and real-time visualization.
In particular, bare metal GPU solutions are a good fit for:
- 3D animation rendering
- Visual effects processing
- Real-time rendering pipelines
- High-resolution video processing
Scientific Research
Researchers running large-scale simulations need high computational resources. Bare metal GPUs have the power and control necessary to run demanding workloads, such as:
- Genomic sequencing and analysis
- Climate modeling simulations
- Particle physics calculations
- Complex scientific computations
How to Choose a Bare Metal GPU Provider
Next to why, the most common question I get from the clients is how to choose bare metal GPU providers.
Choosing the right provider involves much more than comparing GPU specifications and pricing. That’s because the wrong choice can impact not just performance, but project timelines, operational efficiency, and long-term scalability.
I consider the following parameters and features when choosing a bare metal GPU provider:
GPU Options and Hardware
First, look at the specific GPU models and how well they match your workload requirements. Popular options include A100, H100, and AMD 1210. Similarly,
you should know about the server optimization, cooling, power delivery, and hardware refresh cycles, as they are critical operational parameters.
Network Topology
Internal networking within servers and between servers can impact performance. Look for providers that implement NVLink connections between GPUs for single-server multi-GPU configurations.
For distributed training across multiple servers, RDMA-capable networking is essential. So, look for providers that offer InfiniBand or RoCE (RDMA over Converged Ethernet) connectivity with low-latency switches.
Providers explain their network topology diagrams, and switching architecture, and provide realistic performance expectations for your specific distributed training scenarios.
Support and Expertise
When looking for bare metal GPU providers, look for providers that offer technical support and staff with AI and ML application hosting knowledge. They should also have AI-specific support tools for faster issue resolution and access to technical advisors for architecture planning
Do not forget to look for providers offering immediate response for critical issues, resolution times under 5 hours for high-priority problems, and 24/7 support availability for production workloads.
Deployment and Management
Look for providers that offer APIs, support for containers (like Docker or Kubernetes), and flexible OS options. The best providers offer APIs that integrate seamlessly with infrastructure-as-code tools like Terraform.
I also prefer providers who offer pre-configured container runtimes optimized for GPU workloads, with support for Docker, Kubernetes, and specialized AI orchestration platforms.
Pricing Transparency
This is another key aspect you have to consider. Look for providers that offer multiple pricing models aligned with different usage patterns. For instance:
- Hourly pricing works well for experimentation and variable workloads
- Monthly commitments often provide significant cost savings.
There are also providers that charge for the time the GPU was utilized. However, when choosing providers, be careful that there are no hidden charges for network transfer, storage, support, or for any setup or migration.
Do You Really Need Bare Metal GPUs?
Finally, I want to discuss the most fundamental question when it comes to bare-metal GPU infrastructure: do you really need bare-metal GPU servers? This is a crucial question because these servers can add significantly to a business’s costs. Let’s discuss the two sides of the question in detail.
When You Might Not Need Bare Metal GPUs
You may not require bare metal for the following scenarios:
- Proof-of-concept projects
- Intermittent workloads
- Small-scale testing
- Development environments
- Low-priority batch processing
When You Definitely Need Bare Metal GPUs
You need bare metal GPUs for the following scenarios:
- Large-scale AI model training
- High-throughput inference services
- Compliance-sensitive workloads
- Real-time processing requirements
- Financial modeling applications
Vendor Example: RedSwitches GPU Servers
RedSwitches offers an extensive range of NVIDIA and other GPUs that offer high computational power and speed to train and deploy ML models, and data processing. Our multi-GPU support helps organizations to scale seamlessly, avoiding the need for migrating to different infrastructure providers.
Unlike rigid bare metal offerings from other providers, RedSwitches offers complete customization of CPU, RAM, storage, and GPU combinations.
When all these services are exceptional, the real differentiator is our server deployment time. While most bare-metal solutions take days or even weeks to provision, RedSwitches can deploy GPU servers within minutes for time-sensitive or fast-scaling projects.
As someone who has deployed several GPU servers, one key factor that most users overlook is the hidden charges. Most providers often include hidden charges for support, migration, or hardware changes. In contrast, RedSwitches maintains a transparent pricing model and offers 24/7 dedicated support to ensure maximum uptime and minimal disruptions.
That said, regardless of the provider you choose, I strongly recommend reviewing customer feedback and testimonials. Real-world experiences often reveal the true performance, reliability, and support quality beyond marketing claims.
Conclusion
A project that requires ultra-low latency, strict data isolation, custom hardware configurations, or high throughput at scale can choose bare metal GPUs as a strategic investment.
Understand your current GPU utilization patterns, assess your compliance requirements, and calculate your true cost of cloud GPU usage over 12 months.
Contact us today to explore tailored bare metal GPU solutions, discuss your requirements, and get started on deploying the performance and reliability your project demands.
Frequently Asked Questions
Common questions about gpu on bare metal servers.
How does high-performance computing (HPC) accelerate machine learning workflows?
Do I need high-performance computing for all machine learning projects?
What are some ways to accelerate machine learning training besides using HPC?
Manasa M
Technical Content Editor
Manasa is a Technical Content Editor at RedSwitches, known for turning complex technical concepts into clear, engaging content. With a background in copy editing, sub-editing, and technical writing, she shapes the blog's guides for accuracy, readability, and search performance.
Narendra Pawar
Data Center Engineer
Narendra Pawar is a Data Center Engineer with over a decade of experience in IT infrastructure, overseeing RedSwitches' Asia data center operations in India. His work spans server installation and maintenance, network administration, and 24x7 data center operations across Linux and Windows.
Jignesh Jethwa
Linux System Administrator (RHCE)
Jignesh Jethwa is a Red Hat Certified Engineer with over seven years of experience managing hosting infrastructure and mission-critical servers. As an L2 systems administrator at RedSwitches, he provisions bare-metal servers via IPMI, hardens systems against DDoS attacks, and keeps Linux and cloud environments stable across Docker, Kubernetes, and cPanel.

Sons Of The Forest Dedicated Server Setup Guide 2026
Set up a Sons of the Forest dedicated server in 2026 with SteamCMD, UDP ports 8766, 27016, 9700, config files, Windows, Linux Docker, backups, and fixes.

Soulmask Dedicated Server Setup: The Ultimate Guide 2026
Set up a Soulmask dedicated server in 2026 with SteamCMD, Windows/Linux app IDs, ports, Docker notes, GameXishu.json, backups, and fixes.

Bannerlord Dedicated Server Setup Guide 2026
Set up a Bannerlord dedicated server in 2026 with SteamCMD, auth token, port 7210, config files, Linux/Windows steps, and fixes for visibility or join issues.
Power Your Next Project With Bare Metal
10 min delivery, zero setup fees, and 24/7/365 human engineers across 20+ global locations.