
Duplicate data is the bane of data management. Duplicate data items in the form of duplicate rows can cause confusion in data analysis that could result in severe consequences in business estimations and daily operations.
The critical challenge in database management is that duplicate rows within a table are a common occurrence.
These duplicates can distort analysis results and consume unnecessary storage space and other server resources.
Thankfully, MySQL provides several methods to efficiently identify and remove duplicate rows. In this comprehensive tutorial, we’ll explore three techniques for removing duplicate rows from a MySQL table.
Let’s start with the prerequisites.
Table Of Contents
- The Prerequisites
- (Optional) Create a Sample Database
- How to Display Duplicate Rows in MySQL
- How to Remove Duplicate Rows in MySQL
- Conclusion
- FAQs
The Prerequisites
Before delving into removing duplicate rows, ensure you have the following:
- Terminal access to a MySQL database server.
- A MySQL root user account
- Basic understanding of SQL queries and database operations.
(Optional) Create a Sample Database
We will start by creating a sample database and table to demonstrate removing duplicate rows. If you’ve already set up a MySQL database for your project, please move on to the next section.
Create the Database
Use the following command to log in to the MySQL shell with root credentials:
# mysql –u root –p
We recommend our detailed tutorial on creating a database in MySQL to understand the intricacies of the database creation process.
Once logged in, run this statement to check the available databases:
mysql> SHOW DATABASES;
The output will show all available databases on the server:

You can either utilize an existing database to create the test tables or create a new database and test tables from scratch. We will take the second option by running the following statement:
mysql> CREATE DATABASE IF NOT EXISTS UserData;

Before working with the database, you need to select it so that all subsequent statements are applied to the selected database. We will use the following commons to select the new UserData database:
mysql> USE UserData;

Add the Table and Insert Test Data
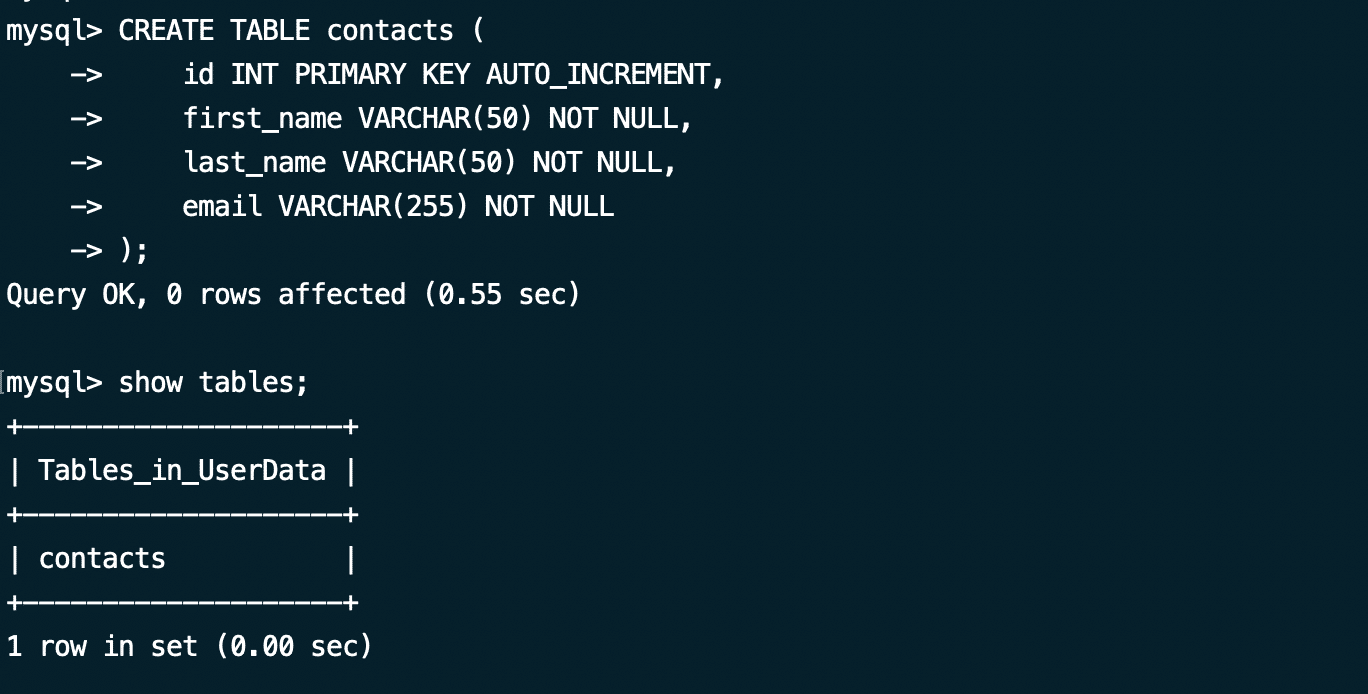
Now, let’s add data by creating a table in the MySQL database with the following statement:
mysql> CREATE TABLE contacts (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
Next, we will add test data to the table with this statement:
mysql> INSERT INTO contacts (first_name,last_name,email)
VALUES ('John','Doe','[email protected]'),
('Jane','Doe','[email protected]'),
('Alice','Smith','[email protected]'),
('Bob','Johnson','[email protected]'),
('Charlie','Brown','[email protected]'),
('Alice','Smith','[email protected]'),
('Eve','Jones','[email protected]'),
('Michael','Davis','[email protected]'),
('Sarah','Wilson','[email protected]'),
('Tom','Taylor','[email protected]'),
('Amy','Robinson','[email protected]'),
('Bob','Johnson','[email protected]'),
('Eve','Jones','[email protected]'),
('Michael','Davis','[email protected]');
Display the Contents of the Table
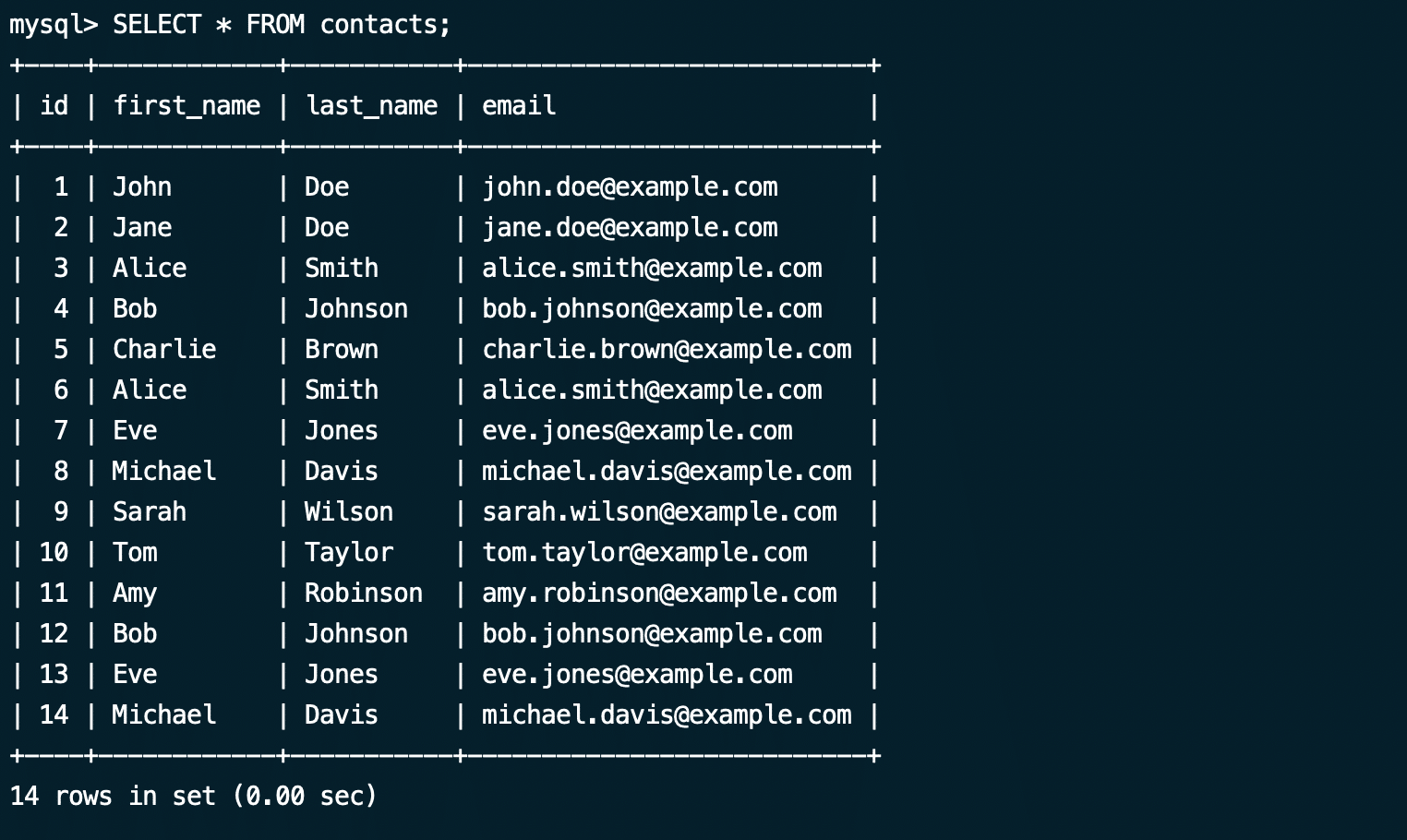
Finally, display the data in the table with the following SELECT statement:
mysql> SELECT * FROM contacts;
How to Display Duplicate Rows in MySQL
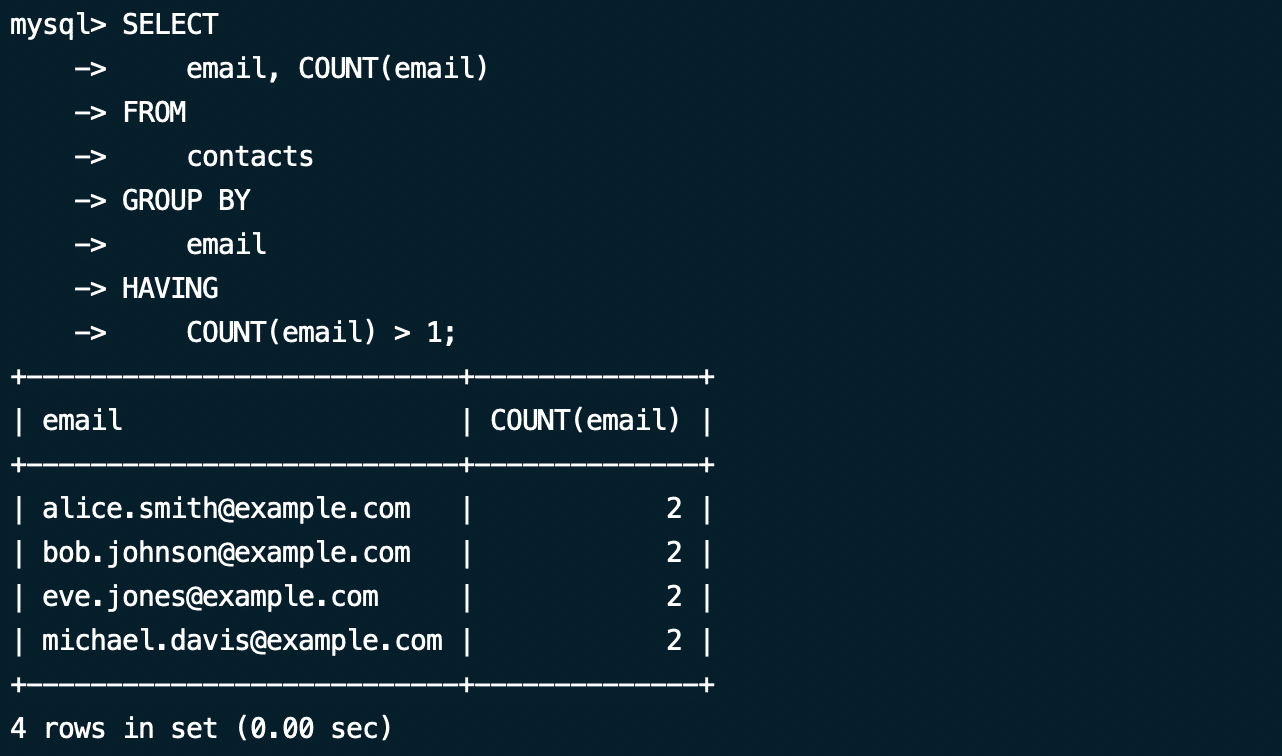
We recommend the following simple SQL query containing GROUP BY and HAVING keywords to identify duplicate rows in a database table:
mysql> SELECT
email, COUNT(email)
FROM
Contacts
GROUP BY
Email
HAVING
COUNT(email) > 1;
How to Remove Duplicate Rows in MySQL
Now, let’s explore the different methods to remove duplicate rows from the sample table.
Method #1: Remove Duplicate Rows by Using INNER JOIN
We can use the DELETE statement with an INNER JOIN, as shown in the following statement block:
mysql> DELETE t1 FROM contacts t1
INNER JOIN contacts t2
WHERE
t1.id < t2.id AND
t1.email = t2.email;
Since we reference the contacts table twice in the query, we utilize table aliases t1 and t2.
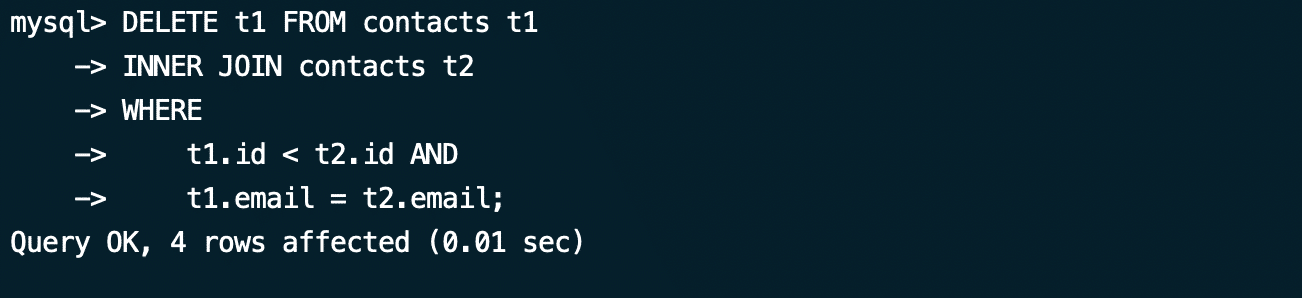
The output confirms that four rows were deleted.
You can rerun the query that identifies duplicate emails to double-check the deletion:

As you can see, the query now shows an empty result set, indicating the successful deletion of duplicate rows.
To confirm, let’s review the data from the contacts table with the following statement:
mysql> SELECT * FROM contacts;
Method #2: Remove Duplicate Rows by Employing an Intermediate Table
This method of eliminating duplicate rows uses an intermediary table. The process starts with a table with an identical structure to the original one. Next, you transfer only the unique rows to it while discarding the duplicates from the source table.
Let’s see these steps in more detail:
Step #1: Create the Intermediary Table
The structure of this table should mirror the structure of the source table. Next, you should transfer the unique rows from the source to this new table.
Run the following statement that achieves this objective:
mysql> CREATE TABLE copy_of_contacts SELECT DISTINCT first_name, last_name, email FROM contacts;

Step #2: Drop the Source Table
Now, you should delete the source table and rename the intermediate table to the source table’s name.
Run the following two statements:
mysql> DROP TABLE contacts;
mysql> ALTER TABLE copy_of_contacts RENAME TO contacts;

Method #3: Remove Duplicate Rows by using ROW_NUMBER()
IMPORTANT: This approach is exclusively applicable for MySQL version 8.0.2 and later. Before proceeding with this method, ensure that your MySQL version meets this requirement by checking the version information in the terminal.
You can use the ROW_NUMBER() window function along with a common table expression (CTE) to assign a unique row number to each row based on specified criteria. You can then use this row number to identify and remove duplicate rows.
The syntax of this statement is as follows:
mysql> SELECT *, ROW_NUMBER() OVER (PARTITION BY [column] ORDER BY [column]) AS [row_number_name];
In our scenario, the statement would be:
mysql> SELECT *, ROW_NUMBER() OVER (PARTITION BY id ORDER BY id) AS row_number;
The result will include a row_number column. Each row is partitioned by id and is assigned a unique row number within each partition.
In this case, the unique values will have a row number of 1, while duplicates will have row numbers greater than 1. So, you can delete rows with row numbers greater than 1 to remove duplicate rows. We recommend the following DELETE statement syntax:
mysql> DELETE FROM [table_name] WHERE row_number > 1;
So, in our scenario, we will apply the following DELETE statement on the example contacts table:
mysql> DELETE FROM contacts WHERE row_number > 1;
The output will mention the number of rows affected, indicating the number of duplicate rows that have been deleted.
You can verify the absence of duplicate rows by running:
mysql> SELECT * FROM contacts;
Also Read: How to Import a CSV File Into a MySQL Database in 2 Simple Methods
Conclusion
By leveraging the various methods outlined in this guide, you can effectively remove duplicate rows from your MySQL tables, ensuring data integrity and improving database performance.
For reliable hosting solutions to support your MySQL databases, consider RedSwitches. Their bare metal hosting services offer robust performance and scalability, providing an optimal environment for your database-driven applications. Whether you require a dedicated server, a traffic-friendly 10Gbps dedicated server, or a high-performance bare metal server, we are here to be your trusted hosting partner.
FAQs
Q. How can I delete duplicate rows in MySQL?
The 3 simple methods to delete duplicate rows in MySQL are using the DELETE JOIN statement, using the ROW_NUMBER() function, creating a new temporary table to store distinct records, and then inserting them back into the original table.
Q. How to find Duplicate Rows in MySQL
To find duplicate rows in MySQL, you can use a SELECT query with the GROUP BY and HAVING clauses. Here’s how you can do it:
SELECT column1, column2, ..., COUNT(*)
FROM your_table
GROUP BY column1, column2, ...
HAVING COUNT(*) > 1;
Replace your_table with the name of your table and column1, column2, etc., with the columns you want to check for duplicates.
Q. Will removing duplicate rows affect other data in the table?
Removing duplicate rows will only affect the duplicated records. Other data in the table remains unaffected.
Q. Is it necessary to create a backup before removing duplicate rows?
While it’s generally a good practice to create backups before making significant changes to a database, removing duplicate rows using the methods outlined in this guide is unlikely to cause data loss if implemented correctly.
Q. Can I schedule the automatic removal of duplicate rows in MySQL?
Yes, you can automate the process of removing duplicate rows by creating scheduled events or using database maintenance tools available in MySQL.
Q. Does removing duplicate rows affect primary keys or indexes in MySQL?
Removing duplicate rows does not directly affect primary keys or indexes. However, it may impact query performance if indexes are affected by changes in data distribution.
Q. Can I remove duplicate rows without deleting data from a MySQL table?
Yes, you can create a new table with distinct rows or use temporary tables to store unique data without deleting rows from the original table.
Q. What precautions should I take before removing duplicate rows in MySQL?
Before removing duplicate rows, it’s essential to back up your data to prevent accidental data loss. Additionally, thoroughly review and test the removal process in a non-production environment.
Q. How can I prevent duplicate rows from appearing in a MySQL table in the future?
You can prevent duplicate rows by enforcing unique constraints on column values, using proper data validation and normalization techniques, and implementing data validation checks in your application code.
Q. Does removing duplicate rows affect foreign key constraints in MySQL?
Removing duplicate rows may affect foreign key constraints if related data is removed. Ensure that foreign key relationships are maintained or updated accordingly to avoid data integrity issues.
Q. What should I do if I encounter a MySQL error while trying to delete duplicate rows?
If you encounter a MySQL error while trying to delete duplicate rows, make sure that you are using the correct syntax for the DELETE statement and that you have the necessary permissions to modify the table.
Q. How can I keep the first occurrence of a duplicate row and delete the rest?
You can keep the first occurrence of a duplicate row in MySQL by using the ROW_NUMBER() function to assign a unique ID to each row and then deleting the rows with IDs greater than 1, effectively keeping the first occurrence.
