

Imagine you own a thriving global eCommerce platform that connects buyers and sellers. Your platform manages a massive influx of data, including user profiles, product listings, transactions, and reviews. However, as the volume of data increases, you’ll find traditional relational databases struggle to cope with the dynamic demands of your platform. Thankfully, non relational databases come to the rescue! With their adaptable structure and scalable design, you can effortlessly store and retrieve vast amounts of user data, handle real-time product updates, and analyze customer behavior patterns while maintaining optimal performance. By embracing the power of non relational databases, you unlock unparalleled scalability, agility, and efficiency in managing your rapidly expanding data-intensive projects. This introduction to non relational databases will cover critical aspects of these platforms and introduce you to some real-world examples and the benefits these databases offer. Let’s start with the fundamentals!
Table Of Contents
- What Are Non Relational Databases?
- Why Use a Non Relational Database?
- What Are the Types of Non Relational Databases?
- The Key Differences Between Non Relational Databases
- How Do Non Relational Databases Work?
- The Benefits of Non Relational Databases
- Real-World Examples of Non Relational Databases
- Which Non Relational Database Should You Use?
- Conclusion
- FAQ
What Are Non Relational Databases?
NoSQL or non relational databases distinguish themselves from traditional relational databases by storing data in a non-tabular format.
Instead, they utilize data structures such as documents. Documents can contain diverse types of information in various formats, allowing for highly detailed and versatile data organization. This flexibility sets non relational databases apart from their counterparts, as they can seamlessly handle and manage different kinds of information.
Non relational databases are commonly employed when there is a need to manage extensive volumes of intricate and heterogeneous data.
For instance, in a retail setting, a sizable store may utilize a database where each customer has a document containing details ranging from personal information such as name and address to comprehensive order history and credit card data.
Note that despite the diverse formats of the information, all these distinct pieces can be efficiently stored within the same document.
Why Use a Non Relational Database?
Non relational databases efficiently handle extensive volumes of diverse and unstructured data.
The most significant benefit of these databases is horizontal scaling for managing big data and high traffic loads. You also get flexibility in data modeling, adapting the current architecture to evolving data structures and dynamic business requirements.
They deliver superior performance in specific scenarios by ensuring faster read and write operations. Moreover, non relational databases boast a schematic design, facilitating seamless modifications to the data structure without affecting data integrity.
What Are the Types of Non Relational Databases?

After that brief introduction, let’s discuss the important types of non relational databases.
Document Based Databases
A document-based database is a non relational database that stores data in documents instead of tables with rows and columns.
The data in a document database is typically stored in JSON, BSON, or XML formats.
Document databases store and retrieve data in a format that closely resembles the data objects used in applications. This reduces the need for extensive data translation and, thus, the complexity of data-processing components.
In a document database, specific elements within the documents can be accessed directly through the assigned index values. As a result, these databases can ensure high query speed.
Collections in a document database are groups of documents that contain similar content. Not all documents belong to a specific collection, as document databases allow flexible schemas.
Popular examples of document-based databases include MongoDB, CouchDB, and Amazon DocumentDB. These databases are widely used in various applications, especially when dealing with semi-structured or rapidly changing data.
Key-Value Stores
A key-value store is a non relational database that represents the simplest form of a NoSQL database.
Each data element is stored as a key-value pair in this database, where a unique key is assigned to each element. The key is used to retrieve the corresponding value from the database. The values can be basic data types such as strings and numbers or more intricate objects.
To visualize a key-value store, consider it a relational database with just two columns: one for the key and the other for the corresponding value.
Key-value stores are designed to be straightforward and uncomplicated. They adopt a minimalist structure facilitating easy comprehension, utilization, and administration. Key-value stores often employ a simplified query model, making them suitable for specific use cases that prioritize simplicity and user-friendliness.
The key-value model is engineered to handle extensive data volumes and high traffic loads efficiently. Techniques like sharding and distributed architectures are commonly utilized to distribute data across multiple nodes or servers. This facilitates horizontal scaling, enabling the system to accommodate growing data sizes and user requests as the application expands.
Similarly, the key-value stores are optimized for rapid read and write operations.
They deliver high-performance data access thanks to their simple structure and efficient indexing mechanisms. Since data is directly accessed using unique keys, retrieval, and storage operations can be exceptionally swift, particularly when compared to other non relational database models.
The key-value stores are an excellent fit for scenarios requiring low-latency data access, such as caching, real-time analytics, and session management.
Column-Oriented Databases
A column-oriented database is a database management system (DBMS) that arranges and stores data based on columns instead of rows.
Unlike a conventional row-oriented database, where data is stored and retrieved by rows containing all attributes of an entity, a column-oriented database stores and accesses data by column. This means that values of a specific attribute across all rows are stored next to each other.
Column-oriented databases make use of specialized compression techniques that effectively reduce storage requirements. By leveraging the repetitive nature of data within columns, compression algorithms efficiently reduce the size of the stored values, resulting in reduced disk space usage.
These databases are particularly well-suited for analytical workloads and complex queries. When executing operations involving aggregations, filtering, or calculations on specific columns, the columnar layout enables efficient data access, as only the query processor needs to access the relevant columns instead of going through the entire database. This leads to improved performance and faster response times in a high query volume situation.
Column-oriented databases excel in aggregating and analyzing vast amounts of data. Since columns are stored separately, the operations like summing, averaging, or counting values within a column can be performed efficiently. This makes column-oriented databases highly suitable for data analytics and business intelligence applications.
Graph-Based Databases
Graph-based databases represent a specific DBMS that employs graph structures for data organization and representation.
In these databases, data entities are represented as nodes (or vertices) interconnected by relationships (or edges). This graph structure facilitates the effective representation and navigation of intricate relationships among data elements.
As a result, graph databases excel at managing and querying data with complex relationships. They provide a natural and intuitive way to model and represent connected data.
Relationships can be easily expressed and traversed, allowing for efficient querying and analysis of relationships between data entities.
Owing to the way they’re organized, graph databases typically have a flexible and schema-less design. This means data can be added or modified without needing a predefined schema or rigid structure. This flexibility enables agile development and accommodates evolving data models.
Graph databases are optimized for handling connected data and performing graph operations. Traversing relationships between nodes can be done efficiently, enabling fast queries and traversals even on large-scale graphs. This makes graph databases particularly suitable for applications such as social networks, recommendation engines, fraud detection, and knowledge graphs.
The Key Differences Between Non Relational Databases
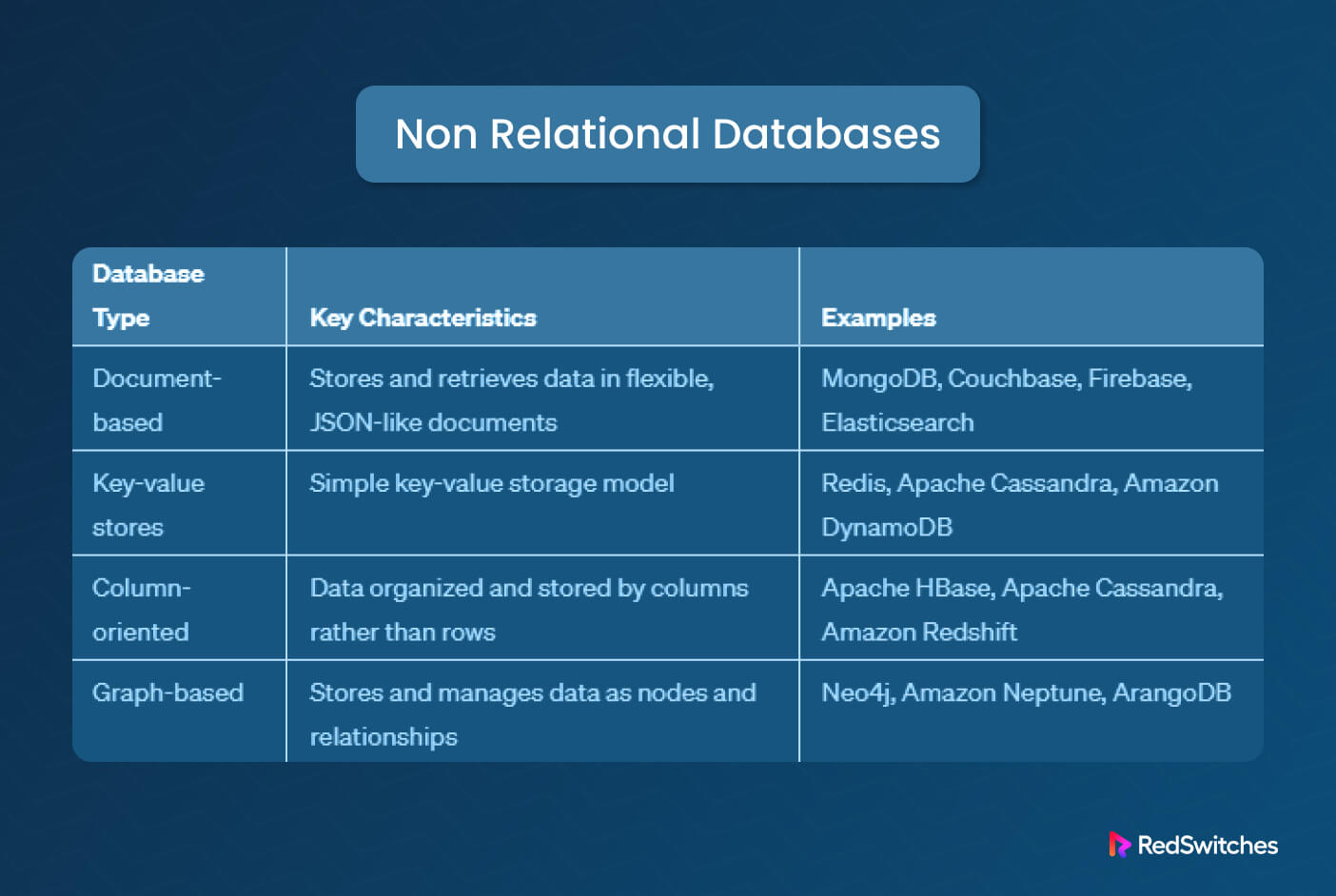
When choosing a non relational database, you need to be aware of the differences in how each type stores data in internal structures. By matching the strength of a database type to your project’s requirements, you can get the most benefit from adding a non relational database to your application.
Document-based databases, such as MongoDB and Couchbase, employ a flexible and schema-less approach to store data in documents with varying structures. These databases are great for managing unstructured or semi-structured data, where adaptability and schema evolution are critical requirements.
As exemplified by Redis and DynamoDB, key-value stores arrange data in simple key-value pairs and offer efficient storage and retrieval operations based on the key.
These databases excel in high-throughput scenarios and caching, making them ideal for applications requiring swift data access based on unique identifiers.
Column-oriented databases, like Apache Cassandra and HBase, optimize data storage and querying by organizing data in columns rather than rows.
This columnar structure enables efficient compression and fast retrieval of specific columns. As such, they are well-suited for use cases that demand scalable and rapid data writes and reads, particularly with large datasets.
Graph-based databases, such as Neo4j and Amazon Neptune, specialize in managing and querying complex relationships between entities. These databases store data as nodes, edges, and properties, facilitating efficient traversal and analysis of intricate relationships. Graph databases are particularly useful for working with interconnections and querying entities’ relationships.
How Do Non Relational Databases Work?
Non- relational databases’ specific workings and features can vary depending on the chosen database technology and its implementation.
However, all non relational databases generally contain the following elements and operational capabilities.
Data Models
Non relational databases utilize diverse data models to organize and represent data. Examples include key-value stores, document stores, columnar databases, and graph databases. Each data model has its unique way of structuring and accessing data.
Schema Flexibility
Unlike relational databases with rigid schemas, non relational databases offer schema flexibility. Each record or document can have a different structure, allowing for adaptable and evolving data models. As a result, these databases can accommodate unstructured, semi-structured, and structured data with equal ease.
Scalability and Distribution
Non relational databases are designed to handle extensive data and high-performance demands. They achieve scalability by horizontally scaling, distributing data across multiple servers or nodes in a cluster. This design is more fault-tolerant and optimizes the consumption of processing and storage capacity.
Replication and Sharding
Non relational databases commonly employ techniques such as data replication and sharding to ensure data availability and performance.
Replication involves creating multiple copies of data across different nodes to provide redundancy and fault tolerance.
Sharding involves dividing data across multiple nodes, distributing the workload, and enabling parallel processing.
The Benefits of Non Relational Databases

Before moving on to the non relational database examples, you must know about the benefits these databases bring to the table.
Easily Scalable Architecture
SQL databases primarily have a scalable-up architecture which depends upon utilizing increasingly powerful computers with additional CPUs and memory to sustain performance.
NoSQL databases were developed near the start of the cloud computing era and thus offer a scalable-out architecture. This is achieved by distributing data storage and processing tasks across a large cluster of computers. In this design, database managers can add more computers (nodes) to the cluster to expand capacity.
Implementing this scalable-out architecture is particularly effortless in cloud computing environments, where adding new nodes (that package processing and storage) to a cluster is straightforward.
The scalable-out architecture of NoSQL systems offers a straightforward approach to achieving scalability when data volume or traffic increases.
Achieving this level of scalability with SQL databases can be costly, necessitate significant engineering efforts, and could introduce points of failure in the database design.
Manage Unstructured, Partially-Structured, or Structured-Type Data
Relational databases store data in a structured table that follows a predefined schema. As such, you must invest time and effort in designing a data model and transforming, translating, and loading the data into the database.
When this data is accessed in applications, it must be retrieved using SQL and translated or transformed to fit the application’s format. Subsequently, when the application needs to write the data back, the data processing components translate or transform the data back into the relational tables data model’s format.
You can imagine the processing capacity and the bandwidth “wasted” on these additional steps.
NoSQL databases have gained popularity because they allow data to be stored in easily understandable ways that better align with how applications use it. This results in fewer transformation requests when the application retrieves and stores data.
Non relational database models can accommodate structured, unstructured, or semi-structured data and facilitate fast storage and retrieval.
Seamless Updates to Schema and Fields
The popularity of NoSQL databases stems from their ability to store data in straightforward and uncomplicated formats, which can be easier to comprehend compared to the data models employed by SQL databases.
Moreover, NoSQL databases often grant developers the ability to modify the data structure directly from the application (although this is not a recommended practice).
In the case of document databases, there is no predefined data structure, allowing for the effortless storage of new document types alongside existing ones.
Key-value and column-oriented stores enable adding new values and columns without disrupting the current structure.
When faced with new data types, developers of graph databases can incorporate new properties to nodes and assign new meanings to relationships.
Developer-Centric
The adoption of NoSQL databases has primarily been ignited by developers who find it more convenient to create diverse types of applications without worrying about adhering to a specific data model mandated by relational databases.
Document databases like MongoDB leverage JSON to transform data into a format resembling code. This grants developers greater control over the data structure of their applications.
Furthermore, NoSQL databases store data in formats that closely resemble the data objects employed in applications. As a result, fewer transformations are necessary when the application moves data in and out of the databases.
NoSQL databases can store data in native formats, eliminating developers needing to adapt the data to fit the storage system. Storing data “as is” removes the need for front-end ETL systems to force-fit semi-structured data into row and column formats and reduces the need for developing or purchasing additional applications to launch a new database.
Real-World Examples of Non Relational Databases
The popularity of non relational databases means you can find a long list of vendors producing and managing their customized implementation of the idea.
We’ll introduce you to the following four non relational databases so that you can understand the value these databases add to applications.
MongoDB
MongoDB is a popular document-based database used by organizations like Forbes, eBay, and Cisco. It is a popular choice for a range of applications, such as content management systems, real-time analytics, and mobile apps.
Redis
Redis is a key-value store that finds applications in caching, real-time analytics, and messaging systems. It is used by companies like Twitter, GitHub, and Craigslist to handle data operations that demand high performance.
Apache Cassandra
Cassandra is a column-oriented database utilized by organizations like Apple, Netflix, and Instagram. It is suitable for handling large volumes of data and delivers high scalability to fault-tolerant distributed systems.
Neo4j
Neo4j is a graph database that powers applications in social networking, recommendation engines, and fraud detection. It is used by companies like Walmart, Airbnb, and Cisco for efficient management and querying of complex relationships.
Which Non Relational Database Should You Use?
After reading all these details about non relational databases, you must wonder which database you should use for your projects.
Selecting the most suitable non relational (NoSQL) database requires considering various factors, including project requirements, data characteristics, and expected workload.
Evaluating each NoSQL database’s features, scalability, performance, community support, and integration capabilities is crucial to ensure it meets the specific project needs.
Additionally, it’s essential to factor in ease of development, maintenance requirements, and the availability of relevant tools and libraries for the chosen database. Considering these aspects is crucial for making an informed decision regarding the optimal NoSQL database for your project.
Conclusion
When managing and processing diverse and rapidly growing datasets, non relational databases offer a powerful alternative to traditional relational databases.
By adopting NoSQL databases, businesses can harness the benefits of scalability, flexibility, and developer-friendly features.
NoSQL databases offer a streamlined approach to handling unstructured, semi-structured, and structured data, allowing for effortless updates to schemas and fields. Their ability to store data in native formats eliminates the complexity of data transformations, resulting in reduced development overhead and improved efficiency.
For organizations in search of reliable and efficient hosting solutions for their non relational databases, Redswitches is a trusted provider offering a comprehensive range of services. With our expertise in scalable and secure hosting infrastructure, we ensure optimal performance through our bare-metal servers. Whether your requirements involve document databases, key-value stores, or columnar databases, we deliver tailored solutions to your needs.
FAQ
Q-1) What is a non relational database?
A non relational database, or NoSQL database, is a DBMS that stores and retrieves data in formats other than traditional structured tables. It offers flexibility in handling unstructured, semi-structured, and structured data.
Q-2) Who uses non relational databases?
Various industries and companies use non relational databases, including Netflix, Airbnb, Facebook, and Twitter. They are ideal for managing diverse data types, handling high traffic, and supporting real-time data processing.
Q-3) How do I choose the right non relational database?
To select the right non relational database, consider factors such as data requirements, scalability needs, performance expectations, and the nature of your application. Evaluate the features and strengths of different database types to find the best fit for your specific use case.
