
In a world that’s increasingly fueled by copious amounts of data, the tools we use to manage, analyze, and interact with this data are of paramount importance. Among these tools, graph databases offer an innovative approach to modeling intricate relational data.
Businesses increasingly rely upon the relationships between data items to understand the underlying trends and use the data in predictive analysis and forecasting.
This blog will cover what is graph DB, the major types and benefits of these databases, and how query language for Graph Databases works in real life.
Table Of Content
- What is a Graph DB?
- Building Blocks of a Graph Database: Nodes and Relationships
- How Do Graph Databases Work?
- Benefits of Using a Graph Database
- Popular Types of Storage & Data Models in Graph Databases
- Query Language for Graph Databases
- Introducing Cypher – A Graph Database Query Language
- The Advantages and Disadvantages of Graph Databases
- Conclusion
- FAQs
What is a Graph DB?
A graph database is a specialized database engineered to store data points and the relationships between those data points. It employs graph structures with nodes (representing objects), edges (representing relationships), and properties (key-value pairs) to represent and store data.
Graph databases emerged as a response to the inadequacies of the conventional relational databases that were increasingly becoming unable to handle complex data produced by social media platforms and similar projects. The main idea was to develop a flexible data storage and manipulation solution for highlighting the data points and the relationships that exist among these points.
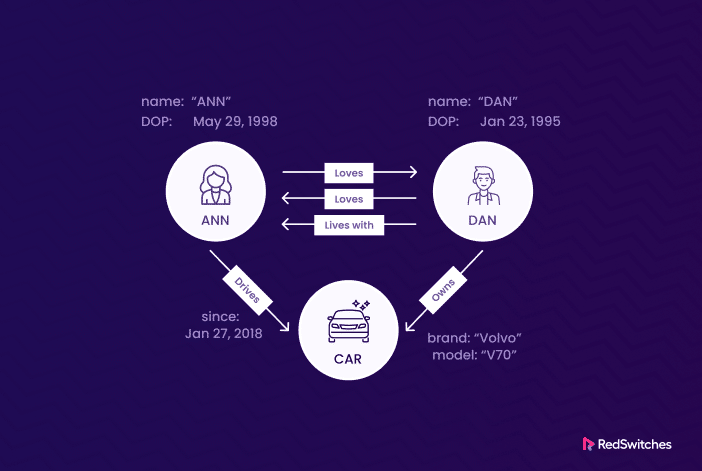
Building Blocks of a Graph Database: Nodes and Relationships
In a Graph Database, think of ‘Nodes’ like rows in a regular database, and ‘Edges’ or ‘Relationships’ as the links that connect these nodes together. What’s unique is that nodes can have all sorts of different characteristics because they don’t follow a strict structure like traditional databases.
Properties of a Graph Database
Prescriptive attributes are like labels with detailed information for nodes and relationships, making queries more powerful.
Popular Graph Database Options
Here are some of the famous graph database options in the market:
- Neo4j: A widely adopted solution with high performance and a friendly developer ecosystem.
- Amazon Neptune: A fully managed Graph Database service by AWS, highly scalable and durable.
- Microsoft Azure Cosmos DB: A multi-model database service supporting graph data through the Gremlin API.
How Do Graph Databases Work?
Think of a graph database as a gigantic mind map or a spider web of information. This web is made up of points (called nodes) and the lines connecting these points (called edges or relationships).
Each node represents an entity, like a person or a movie. The edges are the relationships between these entities. For example, in a movie database, a node could represent an actor, another node could be a movie, and the edge between them could represent the ‘acted in’ relationship.
When you want to find information in a graph database, it’s like starting at one point on the web and following the threads. This differs from traditional databases, where you’d have to look into each box (or table) separately.
Graph databases are great at preserving relationships between data items and speeding up data access and retrieval.
For instance, if you want to find out what other movies an actor has acted in, the graph database directly takes you from the ‘actor’ node along the ‘acted in’ edges to quickly find all other connected ‘movie’ nodes.
Graph databases excel at handling complex and connected data. By directly linking related data, they can quickly answer queries about how data items are interrelated.
Remember, the strength of graph databases lies in tackling relationships and networks of data, while traditional databases would struggle to make these connections efficiently.
Benefits of Using a Graph Database
Graph databases offer three critical benefits, distinguishing them from popular database types.
- Performance: By storing relationships as first-class objects, complex queries execute faster, making them ideal for real-time data analytics.
- Flexibility: Unlike the rigid schema of relational databases, the schema-free nature of graph databases adapts better to evolving business needs.
- Agility: The flexibility in structure allows for easy data extraction and manipulation. As a result, the applications using graph databases respond significantly faster than other database types.
Popular Types of Storage & Data Models in Graph Databases
Storage Models
- Native Graph Databases: These databases store data natively as graphs. The design of these databases includes nodes for entities and edges (or relationships) to express the associations between nodes. Graph databases like Neo4j are examples of native graph databases.
- Non-Native Graph Databases: Some databases aren’t natively built to store data in the form of nodes and edges. However, these databases have a layer to interpret and manipulate the stored data in the form of nodes and edges. For instance, graph databases are built on top of a NoSQL database like Amazon Neptune.
Data Models
- Property Graph Model: This is one of the most common types of graph database models. Each node (or vertex) and edge has a defined set of characteristics called properties, much like columns in a table in a relational database. An edge in a property graph database has both a direction and a type to provide context to the relationship between nodes.
- Hypergraph Model: A relationship (edge) connects only two nodes in typical graph data models. However, in the Hypergraph model, each hyperedge can connect any number of nodes. Thus, it provides a more sophisticated way of expressing complex relationships and high-dimensional data.
- Triple Store Graph Model: This model stores data as triples. Each triple consists of a subject, predicate, and object — representing the entity, its attribute, and the value of that attribute, respectively. Popular in semantic web technologies, this data model abundantly defines relationships and easily merges data across disparate sources.
Query Language for Graph Databases
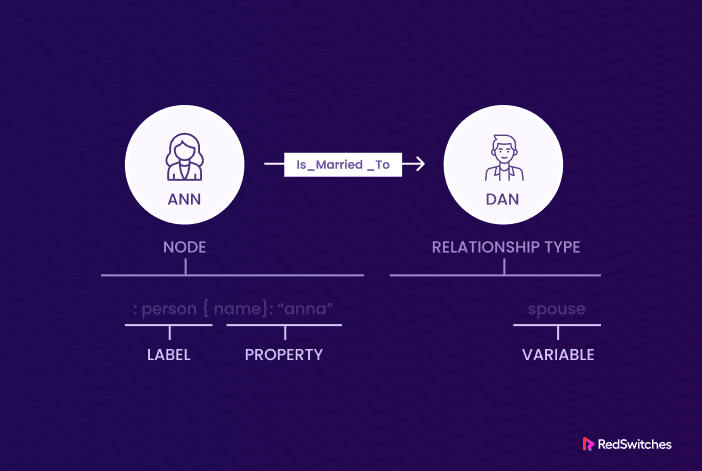
Graph databases offer specialized query languages for data interaction and manipulation. Popular options like Neo4j’s Cypher and Gremlin allow users to use the graph databases’ unique mechanisms.
We’ll use Cypher to illustrate how these specialized languages simplify data retrieval and manipulation.
Introducing Cypher – A Graph Database Query Language
Cypher is a query language designed for interacting with graph databases, particularly in the context of Neo4j, a widely used graph database management system.
The language is designed to efficiently and intuitively navigate, retrieve, and manipulate data stored as nodes, relationships, and properties within a graph.
In a Cypher query, you utilize a pattern-based syntax to specify the graph pattern you wish to match. This pattern includes nodes, relationships, and their optional properties. Each element of the pattern is denoted by a variable, which you can later reference in the query.
The basic structure of a Cypher query is as follows:
MATCH (variable1:Label1)-[variable2:REL_TYPE]->(variable3:Label2)
WHERE <conditions>
RETURN <what to return>
Here’s a brief explanation of this query:
MATCH: This section defines the graph pattern you want to find. It identifies the nodes and relationships you wish to match in the graph. Each element is assigned a variable (e.g., variable1, variable2, variable3), and you can also specify labels and relationship types if needed.
WHERE: This clause is optional and allows you to set conditions to filter the matched patterns. You can use logical and comparison operators to define these conditions.
RETURN: In this clause, you specify what you want to retrieve from the data store. This could include node properties, relationship properties, or other calculated values based on the matched data.
For example, consider a graph database representing a social network, where nodes represent users and relationships represent friendships between users.
Each user node has a “name” property.
The Cypher query to find all friends of a user named “John,” would look like this:
MATCH (john:User {name: 'John'})-[:FRIEND]->(friend:User)
RETURN friend.name
In this query:
(john:User {name: ‘John’}): Matches a node with the label “User” and the property “name” equal to ‘John’ and assigns it the variable john.
-[:FRIEND]->: Matches outgoing relationships of type “FRIEND” from the john node to other nodes.
(friend:User): Matches the nodes connected to john by the “FRIEND” relationship and assigns it the variable friend.
RETURN friend.name: Returns the “name” property of the matched friend nodes.
The Advantages and Disadvantages of Graph Databases
Graph databases are judged based on four key metrics: integrity, performance, efficiency, and scalability.
The core objective of graph databases is to enhance the speed of data access and simplify the query process.
During comparison, when relational databases hit their performance ceiling, graph databases continue to function and are largely unaffected by data volume or complexity during the query process.
Furthermore, graph databases are adept at replicating real-world relationships among entities. The database’s structure mirrors how people perceive a dataset as a collection of data points and relationships.
However, graph databases are not a fix-all solution. They encounter bottlenecks, predominantly with scalability. As they are essentially designed for single-tier architecture, expansion, and scalability present a severe challenge.
Additionally, graph databases don’t have a standardized query language.
Here is a quick look at the pros and cons of graph databases:
| Advantages | Disadvantages |
| Query speed is reliant solely on the number of actual relationships, irrespective of overall data volume | Challenges with scalability due to one-tier architecture design |
| Real-time results | Absence of a standardized query language |
| Transparent and manageable relationship portrayal | |
| Versatile and agile architecture |
Graph databases should not be viewed as a superior replacement for traditional databases. The rationale behind relational structures as standard models remains valid, as they ensure high data integrity and stability while providing flexible scalability. Therefore, the choice always hinges on the specific use case in question.
Conclusion
As we navigate the big data era, questions such as what is a graph database offer challenges that can only be resolved by using graph databases. These databases promise an innovative and effective approach for handling complex data relationships and deriving meaningful insights. Despite certain challenges, their rapid adoption speaks volumes about their potential to be a game-changer in data handling and management.
At RedSwitches, our support engineers help customers manage their Linux-based servers that host graph databases and related projects. Our support is available round-the-clock and proactively resolves your issues on priority.
Contact us now to learn more.
FAQs
Q. When should I use a graph database?
A. Graph databases are ideal when your data contains complex many-to-many relationships and when performance for querying these relationships matters.
Q. Are graph databases only used for big data applications?
A. While graph databases efficiently deal with big data scenarios, they aren’t limited to handling extensive data sets. These databases suit scenarios where relationships are as valuable as data points.
Q. Can graph databases replace SQL databases?
A. Not necessarily. The choice between a graph or SQL database largely depends on your use case’s specific requirements and data relationships.
Q. Can graph databases handle real-time data analysis?
A. Yes, graph databases can analyze sophisticated real-time data by swiftly executing complex relational queries.
Q. How are graph databases different from document databases?
A. Although both are types of NoSQL databases, document databases centralize around ‘documents’ – independent data units, while graph databases focus on ‘relationships.’
