
Relational database normalization is a fundamental principle in database design that enhances data storage, integrity, and efficiency.
Normalization minimizes redundancy, ensures data consistency, and simplifies database management by systematically organizing data into logical structures.
In this article, we’ll examine the concept of relational database normalization and its vital importance in maintaining well-organized databases. We will provide a comprehensive guide to normalizing a database, enabling you to understand the first normal form, the second normal form, and the third normal form of a database.
Let’s start with a basic overview of database normalization.
Table of content
Understanding Database Normalization
Database normalization is critical in creating properly organized tables with columns and keys. The core idea is to break up a large (generally unorganized) table into smaller logical units. This process considers the database’s environment and how the designers and developers plan to use it in business processes.
Normalization is an iterative process involving multiple decomposition steps, leading to a more organized and manageable database.
Another important aspect of this process is that it’s an ongoing process. Databases in a business environment are subject to design changes. There’s always a chance that adding or dropping a table might affect the normalization state. Experts suggest periodically reviewing the exercise to ensure database modularity and efficiency by reducing redundancy and improving data consistency.
The Importance of Relational Database Normalization
Database normalization eliminates attributes with multiple values, duplicated or repeated attributes, non-descriptive attributes, redundant information, and attributes derived from other features.
Although all databases may not need complete normalization, they can always benefit from the final highly-functional information environment that results from the process.
The normalization process systematically ensures the following:
- Data is organized logically and structured. The emphasis of the process is on improving data integrity and accuracy.
- Redundancy is minimized, leading to efficient storage utilization and reduced memory requirements.
- Data dependencies are correctly defined, promoting consistency and preventing data anomalies.
- Database maintenance and updates are streamlined. This ultimately reduces the risk of data inconsistencies.
- Faster and more efficient data retrieval, thanks to query performance optimization.
- The database design becomes more scalable and adaptable to future changes and expansions.
- The overall database quality and reliability are enhanced, resulting in a robust and well-designed system.
Database normalization ultimately transforms the overall consistency of the database, providing an efficient and robust environment for data storage, retrieval, and management.
The Challenge of Database Redundancies and Anomalies
Database normalization addresses the issues of redundancies and anomalies that can arise in unoptimized database tables.
Redundancy in data is a serious problem, especially for large databases. That’s because modifying a single entity requires updating all instances of the redundant information and related data. In addition to investing resources into the process, failure or delays in updates result in an inconsistent database and introduce anomalies during data changes.
Let’s consider an example of an unnormalized table to understand these challenges:
Unnormalized Table: Employee Data

You can see that this table has data redundancy, specifically in the “Department” column.
Consequently, when a user tries to modify data, three anomalies would result:
Insert anomaly: When inserting information about a new employee in the Finance department, it is necessary to provide the manager’s name. Failure to do so would make inserting the data into the table impossible.
Update anomaly: The associated manager’s name becomes incorrect if an employee changes departments. For instance, if John moves to the finance department, his manager would be Joshua. However, the manager’s name in the database would remain Adam, leading to inconsistency.
Delete anomaly: When deleting Joshua’s row, the information about the finance department is also lost. This deletion can result in the loss of essential data.
The database admins can resolve these anomalies by applying the concepts and steps in database normalization.
The admins can eliminate redundancies and mitigate these anomalies by normalizing the table and splitting it into smaller, more logically organized units, such as separate employee and department tables.
Let’s discuss these principles in more detail.
The Principles of Database Normalization
The fundamental principles employed in database normalization include the following:
- Keys: Column attributes that uniquely identify a database record.
- Functional Dependencies: Constraints that define the relationship between two attributes within a relation.
- Normal Forms: A set of guidelines or steps to achieve specific levels of quality and organization in a database.
The Database Normalization Levels
Database normalization involves applying a set of guidelines called normal forms (usually, the first normal form (1NF), the second normal form (2NF), and the third normal form (3NF)) to assist database designers in achieving their desired level of quality in a relational database.

Each level of normalization builds upon the previous ones. As such, the designers must satisfy all the previous normal form’s requirements before proceeding to the next form.
The stages of normalization include:
| Stage Name | Redundancy Anomalies Addressed |
| UNF-Unnormalized Form | Redundant and complex values in the initial state. |
| 1NF-First Normal Form | Repeating and complex values split up to make instances atomic. |
| 2NF-Second Normal Form | Partial dependencies are decomposed into new tables. |
| 3NF-Third Normal Form | Transitive dependencies are decomposed into new tables. |
| BCNF-Boyce-Codd Normal Form | Transitive and partial functional dependencies are decomposed. |
| 4NF-Fourth Normal Form | Multivalued dependencies are removed. |
| 5NF-Fifth Normal Form | JOIN dependencies are removed by creating separate tables. |
Usually, designers consider a database normalized when it satisfies the requirements of the third normal form. Going for further normalization forms is a matter of preference. However, we recommend proceeding with caution because these steps could introduce complexities in the database design and potentially compromise the system’s functionality.
The Role of Database Keys
A database key refers to an attribute or a group of attributes that uniquely identify an entity within a table.
The following types of keys play a critical role in the normalization process:
- Super Key: A set of attributes that uniquely identifies each record in a table.
- Candidate Key: A carefully chosen key derived from the set of super keys. These keys are used to minimize the required fields.
- Primary Key: A table’s primary key is determined by selecting the most suitable choice from the available candidate keys.
- Foreign Key: A primary key from a different table that establishes a relational link between the two tables.
- Composite Key: A unique key formed by combining two or more attributes, where the individual attributes are not considered keys independently.
As tables undergo decomposition into multiple simplified tables, keys play a crucial role in serving as reference identifiers for database entities.
For instance, consider the following example table in a database:

In this table, we can observe various super keys:
- employeeID
- (employeeID, name)
Note that attributes such as the employee’s name or age cannot be used as unique identifiers due to the possibility of multiple individuals sharing the same name or age.
The candidate keys, on the other hand, are selected from the set of super keys. In this case, two options stand out:
- employeeID
Both options, employeeID and email, serve as suitable candidate keys. However, there’s a strong possibility that user email addresses might change as businesses adopt a new system or expand their current email systems. employeeID is the preferred choice for the primary key in this case.
The database designers can use this primary key in other tables as a foreign key to link the tables and establish relationships.
What are Functional Dependencies in Databases
Functional database dependencies represent relationships between attributes within a database table. Various functional dependencies include
- Trivial Functional Dependency: A dependency where an attribute is already present in the group of attributes it depends on.
- Non-Trivial Functional Dependency: A dependency where an attribute is not initially part of the group it depends on.
- Transitive Dependency: A dependency between three attributes, where the second attribute depends on the first, and the third attribute depends on the second. This transitive nature causes the third attribute to be indirectly dependent on the first attribute.
- Multivalued Dependency: A dependency where multiple values depend on a single attribute.
Functional dependencies play a vital role in database normalization. Over time, these dependencies contribute to determining the overall quality of a database.
The Process of Relational Database Normalization
The process of database normalization follows a set of general steps that can be applied to any database.
You should note that this process will cover the first normal form, the second normal form, and the third normal form of a test database. After 3NF, the database is generally optimized enough for most business applications.
Let’s begin.
Consider the following un-normalized database containing a single un-normalized table. This table contains multiple values in a single field and includes redundant information.
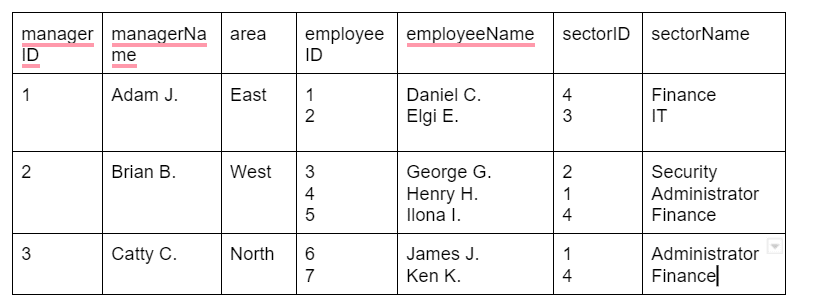
You can imagine the problems in data insertion, updating, and removal. More significantly, modifying the table carries a significant risk of data loss.
Let’s run through the normalization process to optimize the structure of this database.
Step 1: Transforming the Database into First Normal Form (1NF)
The first normal form (1NF) is achieved when the values within a single field are atomic (individual values that can’t be further divided). In addition, any complex entities in the table should be divided into new rows or columns.
For instance, in the test table, the fields employeeID, employeeName, sectorID, and sectorName contain multiple values that can be atomized.
The following table shows each field containing a single atomic value. This ensures that no information is lost during table manipulation.
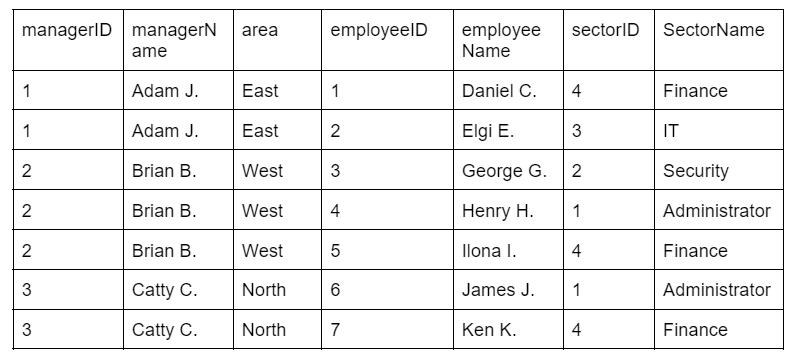
The modified table now meets the requirements of the first normal form (1NF).
Step 2: Second Normal Form (2NF) Transformation
According to the second normal form (2NF) in the database normalization process, each row in the database table should depend on a primary key.
The test table is divided into the following two tables to fulfill this requirement:
Manager (managerID, managerName, area)

Employee (employeeID, employeeName, managerID, sectorID, sectorName).
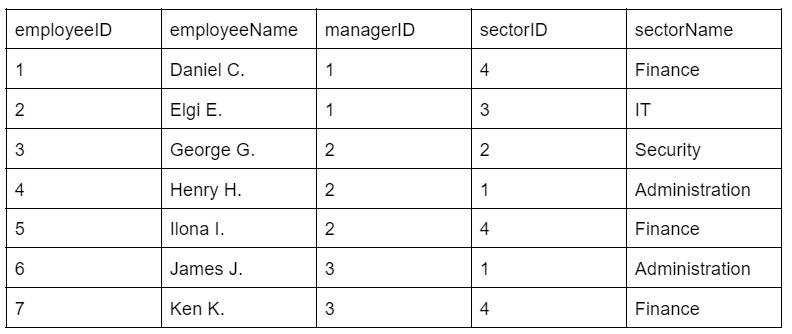
The resulting database, now in the second normal form, consists of two tables and is free from any partial dependencies.
As you can see, the Employee table uses managerID as the foreign key to link the two tables and set up a relationship.
Step 3: Third Normal Form (3NF) Transformation
The third normal form (3NF) focuses on decomposing any transitive functional dependencies.
In the current table, the Employee table exhibits a transitive dependency (sectorID and sectorName), which necessitates decomposition into two new tables:
Employee (employeeID, employeeName, managerID, sectorID)
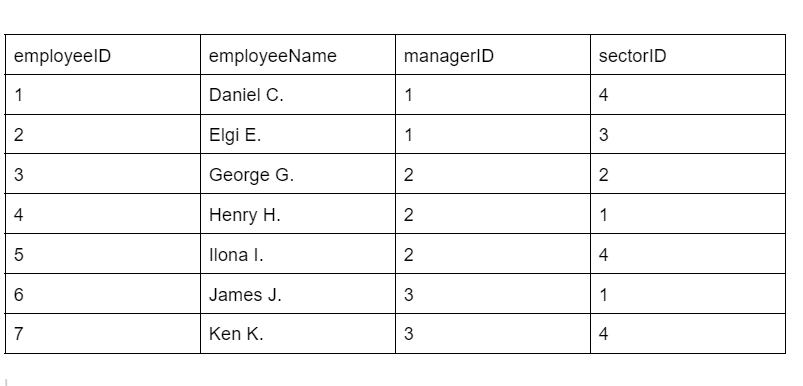
Sector (sectorID, sectorName)
| sectorID | sectorName |
| 1 | Administration |
| 2 | Security |
| 3 | IT |
| 4 | Finance |
The test database now has three tables (Employee, Manager, and Sector). At this stage, it has achieved 3NF.
The final structure is as follows:
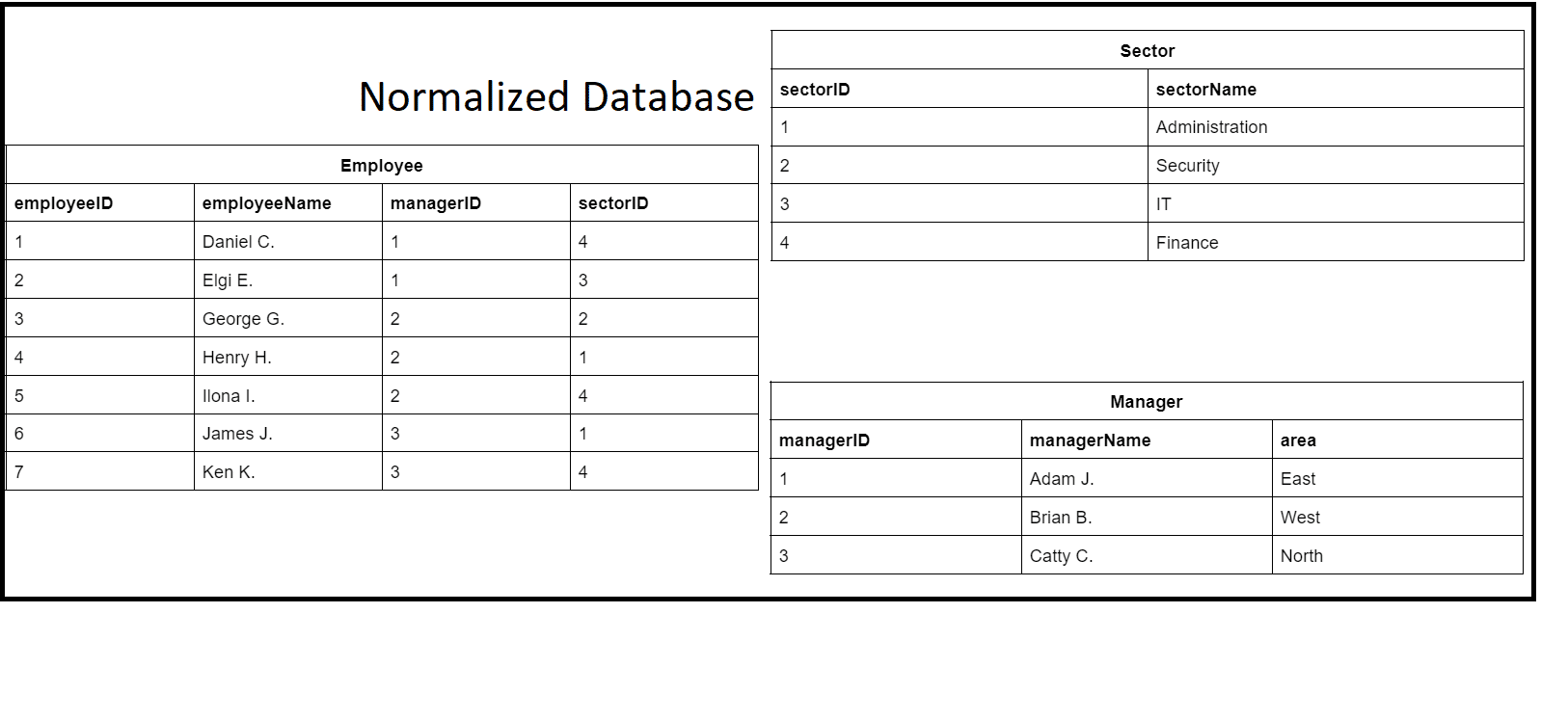 At this stage, the database has achieved normalization. Any additional normalization steps will vary depending on the specific use case and data requirements.
At this stage, the database has achieved normalization. Any additional normalization steps will vary depending on the specific use case and data requirements.
Conclusion
Relational database normalization is a crucial process that helps improve a database’s quality, efficiency, and organization. Following normalization steps, such as reaching the desired normal form and resolving functional dependencies, the database becomes more robust and less prone to data anomalies.
We discussed the normalization process and reviewed the details of the first normal form, the second normal form, and the third normal form of a database.
RedSwitches, a leading bare metal dedicated hosting provider, can assist you in optimizing your database and ensuring its optimal performance. Contact our team today to leverage their expertise to set up optimized hosting servers for your business databases.
FAQs
Q. Why is database normalization necessary?
Database normalization is essential because it helps reduce data redundancy, improve data consistency, and enhance data integrity. It also facilitates efficient data querying and modification operations.
Q. What are the benefits of normalization?
The benefits of database normalization include:
- Elimination of data redundancy and inconsistency
- Improved data integrity and accuracy
- Simplified data maintenance and updates
- Enhanced query performance and efficiency
- Facilitates database design and scalability
Q. Can normalization be applied to an existing database?
Yes, normalization can be applied to an existing database. However, it may require restructuring the data model, modifying tables, and ensuring data integrity during normalization.
Q. What are functional dependencies in database normalization?
Functional dependencies represent relationships between attributes in a database table. They describe how the values of one or more attributes determine the values of other attributes.
