
Welcome to our in-depth examination of Redis and Memcached, two potent in-memory data storage solutions. Selecting the appropriate technology might be crucial for optimizing your applications in the rapidly evolving field of data management. This blog post will examine Redis and Memcached’s basic definitions and their unique qualities, advantages, and disadvantages.
We’ll concentrate on a thorough comparison, “Redis vs Memcached: 15 Key Differences.”
By the end, you’ll know exactly which solution best suits your unique requirements and when Redis is the better option and Memcached is the better one. Let’s go on this illuminating adventure to strengthen your decision-making abilities. We shall also discuss memcached vs redis performance.
Let’s Begin.
Table Of Contents
- What is Redis?
- What is Memcached?
- Memcached vs Redis: What’s the Difference?
- Redis vs Memcached: Data Types
- Redis vs Memcached: Persistence
- Redis vs Memcached: Data Length
- Redis vs Memcached: Data Eviction Policies
- Redis vs Memcached: Replication
- Redis vs Memcached: Clustering
- Redis vs Memcached: Performance
- Redis vs Memcached: Availability
- Redis vs Memcached: Pricing and Scalability
- Redis vs Memcached: Multithreading
- Redis vs Memcached: Ease of Use
- Redis vs Memcached: Supported Languages
- Redis vs Memcached: Data partitioning
- Redis vs Memcached: Transactions
- Redis vs Memcached: Geospatial support
- When to Use Memcached?
- When to Use Redis?
- Conclusion
- FAQs
What is Redis?
Credits: Redis
Redis, a Remote DIctionary Server, is an open-source NoSQL key/value store running entirely in memory. It is mainly utilized as an application cache and quick-response database. Since it keeps data in memory rather than on a disc or solid-state drive (SSD), Redis offers unmatched speed, dependability, and performance.
Key Features of Redis
Let us understand the key features of Redis in detail.
Data Stored in Memory
Since Redis is a fully in-memory data store, all of its data is kept in the server’s memory. This design option is ideal for applications where quick access to data is essential since it offers excellent speed and little latency.
Structures of Data
Redis provides a variety of data structures so developers can select the best one for their particular use case:
● Strings
Redis strings are flexible for various use cases, including caching and session management, because they are binary-safe and may store any kind of data.
● Lists
Lists are ordered collections of elements that support range, push, and pop queries. They help implement features like activity feeds and message queues.
Also Read: How To Install Redis on macOS: 2 Scenarios
Operations and Commands
Redis offers a wide range of commands that work with the previously stated data structures. Developers can carry out intricate tasks with little difficulty because of these commands’ simplicity, atomicity, and speed. Set, get, increment, decrement, push-pop, and different set operations are a few frequent operations.

Credits: Freepik
Options for Persistence
Redis has various options for persistence to guarantee data durability and recovery in the event of failures:
● RDB (Redis Database) Snapshots
These are disk-stored point-in-time copies of the dataset. Redis can be a backup by periodically saving these snapshots to a disc. On the other hand, if Redis crashes between two snapshots, RDB snapshots may result in data loss.
● Append-Only File, or AOF Persistence
AOF persistence logs each write operation the server receives to ensure the dataset can be rebuilt following a crash. Rewriting AOF files can help control their size and prevent them from using too much disk space.
● Merging RDB and AOF persistence
AOF persistence logs each write operation the server receives to ensure the dataset can be rebuilt following a crash. Rewriting AOF files can help control their size and prevent them from using too much disk space.
Replication
Redis allows asynchronous data copying from a master Redis server to several slave servers via master-slave replication. Replication makes distributed architectures possible by offering read scalability and fault tolerance.
Partitioning and Sharding
Redis supports partitioning and sharding, allowing for horizontal scaling over several nodes. This feature makes it appropriate for big data applications, as it guarantees that it can manage huge datasets and high request rates.
Pros and Cons of Using Redis

Let’s have a look at the Advantages and Disadvantages of using Redis.
Pros
- It’s rapid. Quicker than other providers for cache out.
- Redis’s straightforward installation makes it quick to use and simple.
- Redis can accommodate most data structures and is adaptable.
- Redis has 512 MB of key-value pairs stored.
Cons
- Redis needs a lot of memory, which is expensive, just like other memory-based databases.
- Anticipate needing to supply more memory than what the data calls for.
- Redis is not appropriate if an OLAP database is required.
- It is not advised to use it on RAM servers due to its in-memory nature.
What is Memcached

Credits: Memcached
Memcached is a high-performance, free, and open-source memory caching solution. It is usually used to cache database data, API calls, or portions of pages rendered in RAM to improve application performance.
It can hold data of any size, up to and including a whole HTML page.
The system is made accessible over TCP, allowing it to operate on a different server or be dispersed over several servers, accumulating data in a large hash table.
Key Features of Memcached
Credits: Freepik
Some of Memcached’s characteristics are as follows:
Simplicity and Ease of Use
One of Memcached’s key advantages is its simplicity. Data is kept in the form of key-value pairs and functions on this basis. With basic get and set operations, applications can store any type of data, including texts, numbers, and sophisticated data structures.
Developers may easily include caching into their applications with Memcached’s simple API and minimalistic architecture, as it doesn’t require a high learning curve.
Distributed and Scalable
Memcached can manage massive volumes of data and traffic because it is made to be both distributed and horizontally scalable. It functions as a system for distributed caching, allowing for smooth expansion over several nodes.
Adding more servers allows the Memcached cluster to expand horizontally to handle more demand without sacrificing performance. Scalability is crucial for contemporary web apps that must manage changing workloads and a rising user base.
Effective In-Memory Caching
Memcached offers incredibly quick read and write access speeds by storing data in the server’s Random Access Memory (RAM). Low-latency retrieval is guaranteed when data is stored in memory, which makes it perfect for caching frequently accessed data, like session data, API answers, and database query results.
With in-memory caching, the strain on backend databases is significantly reduced, improving application performance overall and resulting in faster response times.

Credits: Freepik
Policies for Cache Expiration and Eviction
Memcached enables developers to specify the expiration dates of objects that are cached, guaranteeing that stale or out-of-date data does not impair the application’s functionality. Memcached automatically removes expired items from the cache, enabling the application to retrieve new data from the source on subsequent requests.
Furthermore, Memcached has effective eviction policies to manage full cache situations. It employs techniques like LRU (Least Recently Used) and LFU (Least often Used) to eliminate less often visited items and create space for new data to maximize cache utilization.
Flexibility and Language Support
Because Memcached is language-neutral, it can be easily incorporated into programs written in several languages. It offers official client libraries for numerous well-known languages, including Python, Java, PHP, Ruby, and many more. Because of this flexibility, developers can select the language that best suits their use case or with which they are most comfortable.
Memcached’s simple and consistent API guarantees a uniform caching experience across many platforms and technologies, regardless of the programming language.
Support for CAS (Compare and Swap) operations
This lets programmers make conditional changes to items that are cached. Before updating a key, an application can use CAS to verify if its linked value matches the intended value.
This functionality guarantees data consistency when several clients access and modify the same cached item concurrently. Because CAS procedures stop race circumstances, developers may preserve the integrity of data that has been cached, which makes Memcached ideal for applications where data consistency is crucial.
Pros and Cons of Using Memcached

Before moving to our core debate, Redis vs MemCached, let’s understand the Pros and Cons of using MemCached.
Pros
- Incredibly quick reaction speeds are made possible by the in-memory key-value storage.
- Computing capacity may be vertically scaled thanks to multi-thread architecture.
- Sophisticated open-source solution with a data store that is accessible to the public
- Simple to use and adaptable for creating new applications
- Supports most popular clients, computer languages, and open data formats.
Cons
- Data is only momentarily stored and is lost if a Memcached instance fails.
- Because data cannot be displayed, debugging is challenging.
- Value keys can only have a maximum length of 250 characters (1 MB).
- More firewalls are required in cases where security measures are lacking.
- Not redundant—that is, not relying on data backups or mirroring.
Memcached vs Redis: What’s the Difference?

Let’s come to the core part of our blog, i.e., the Memcached vs Redis debate. This section will discuss 15 critical differences between memcached and redis.
Redis vs Memcached: Data Types
Redis
Redis offers a wide range of native data types, which makes it a solid and adaptable caching solution. These data types are bitmaps, hashes, strings, lists, sets, sorted sets, and hyperloglogs. Redis has distinct use cases for each data type, allowing developers to model their data more efficiently.
Memcached
Regarding data types, Memcached saves data as strings, and Redis stores data as distinct types. Redis can thus modify data in place without necessitating a new upload of the complete data value, decreasing network overhead.
All data is kept in Memcached as strings, regardless of how it was originally formatted. Although this simplicity makes storing and retrieving data faster and more effective, it also makes Memcached less capable of directly handling complicated data structures.
As a result, complex data types must frequently be serialized and deserialized into strings by developers before being stored in Memcached, which adds another level of complexity to the application code.
Redis vs Memcached: Persistence
Redis
Redis offers persistence to the disc, which means that if the Redis server crashes or needs to be restarted, the data stored in the database can be restored. Despite its incredible speed, memory has the drawback that its data is lost in the event of a server failure.
Redis’ persistence isn’t completely safe; data may alter for a few seconds to several minutes, depending on the kind employed. Nevertheless, any persistence is preferable to none at all.
Redis provides atomic operations, which enable programmers to execute several commands within a single atomic transaction. This ensures data consistency and integrity by executing every command in the transaction or not executing any of them.
Redis additionally facilitates pipelining, which simultaneously sends several commands to the server simultaneously, lowering the round-trip time between the client and the server. By reducing network latency, this feature improves the effectiveness of write-intensive applications.
Memcached
Memcached does not handle disc persistence natively. Memcached has no built-in means for persisting data to disc because it is intended to be a pure in-memory caching solution.
Therefore, all of the data kept in memory is lost if a Memcached server crashes or restarts. Although Memcached performs exceptionally well in high-performance caching settings, it is best suited for use cases where data loss may be accepted, and the data can be recreated from the source if needed because it lacks native disc permanence.
Redis vs Memcached: Data Length
Redis
Redis data keys and strings have a maximum length of 512 MB (megabytes). However, it is usually not advised to use strings larger than this for performance-related reasons. You can also store any form of data, even JPEG images, because they are binary secure.
Data keys and strings in Redis have a maximum size of 512 MB (megabytes). Although there is an upper limit, using strings, this large is generally discouraged because of performance-related issues.
Large strings can greatly affect Redis’s speed, especially regarding memory usage and general responsiveness. Even while strings this length can be handled, developers usually aim for shorter lengths to preserve effective database operations.
Memcached
Memcached has a maximum value of 1MB by default and only accepts keys of 250 bytes (but you can change this) rather than attempting to get past these restrictions.
Memcached has stricter restrictions. It limits a stored value’s maximum size to 1 MB by default and supports keys up to 250 bytes long. The primary limitation still stands: Memcached performs better when handling smaller data objects, even though configuration can change these restrictions.
Redis vs Memcached: Data Eviction Policies
Redis
To address data eviction, Redis provides several other options. These include Volatile TTL (Time to Live), which allows Redis to try removing keys with a set TTL first to preserve data that was not annotated with a TTL and was intended to persist for a more extended period, and No Eviction, which allows the memory to fill up and then stops accepting any more keys.
Memcached
Least Recently Used (LRU) Data Eviction is a widely adopted strategy in computer systems for efficiently managing memory or cache space. It operates on a simple principle: data that hasn’t been accessed or used recently is considered less important and is, therefore a candidate for removal when space is needed. This method is based on the observation that data accessed recently is more likely to be needed again soon, making it a priority to keep.
The LRU algorithm plays a crucial role in caching systems such as Memcached. Memcached, specifically, uses LRU for managing its cache. When a new data item needs to be stored, and the cache is complete, the system identifies the least recently used data and removes it to make room. This ensures that the cache retains the most relevant data. It’s important to note that if data in the cache is accessed (a ‘hit’), it is then considered recently used and is not a candidate for eviction, thus remaining in the cache.
Redis vs Memcached: Replication
Redis
Redis allows for replication, which enables you to duplicate your Redis dataset across one or more slave nodes. Redis uses asynchronous replication, which means that data is replicated from the master asynchronously by the slave nodes.
This configuration offers fault tolerance and high availability. In a Redis replication system, the slave nodes replicate the data using a constant stream of orders from the master node.
Memcached
However, built-in replication is not supported natively by Memcached. Each server node in Memcached’s distributed, decentralized architecture is independent of the others.
Replication in Memcached is usually managed at the application level. Developers must achieve replication and high availability using third-party solutions or implementing bespoke logic. Data sharding and maintaining numerous duplicate Memcached clusters are popular strategies.

Credits: Freepik
Redis vs Memcached: Clustering
Redis
Redis offers clustering, which lets you spread data among several nodes for increased fault tolerance and scalability. Redis Cluster employs a partitioning technique called hash slots, assigning a unique slot to every key.
The Redis Cluster’s nodes share these slots, which are separated into sections of the key space. Because each node is in charge of a portion of the hash slots, the cluster can grow horizontally due to this distribution.
Memcached
Traditionally, clustering has not been supported natively by Memcached. It is based on a straightforward, decentralized design in which every Memcached server runs separately. A technique known as “sharding” is frequently used by developers to accomplish clustering and horizontal scalability. The client application in Memcached sharding chooses which server to use for a given key.
Redis vs Memcached: Performance
Redis
Redis’s in-memory architecture makes data retrieval nearly quick, which makes it perfect for applications requiring real-time responsiveness. Redis also supports complicated data structures, such as hashes, lists, sets, and strings. These native data structures provide for developers’ efficient and intuitive data modeling, allowing for complicated operations without compromising performance.
Memcached
Memcached is also an in-memory caching technology; it uses a less complex data model than Redis. For small data chunks, it is especially effective when storing data as key-value pairs. Memcached’s simplicity and ease of use are its main advantages. Memcached dramatically speeds up application response times by eliminating the need for repetitive database queries by keeping frequently visited data in memory.
Redis vs Memcached: Availability
Redis
Applications can have high availability when clustering and replication are used together. Several master instances and linked replicas can be used to set up a Redis cluster.
If a single master in the cluster fails, the replica will take over as master and be elevated to master automatically.
The failing instance will automatically sync as the replica for the new master when it returns online. For redundancy, replicas might be stored on different racks.
Redis also makes use of a potent instrument known as Sentinel. Sentinel nodes are in charge of monitoring the condition of Redis slave and master nodes. The Sentinel mechanism arranges for a suitable slave to be promoted to become the new master if a master node is inaccessible.
Sentinel can also handle configuration updates, notifications, and failover, ensuring the Redis cluster maintains high availability despite changing circumstances.
Memcached
Memcached does not come with built-in failover capabilities. Other techniques and technologies, such as adding load balancers and monitoring systems, are frequently used to improve Memcached’s availability.
These external components assist in managing traffic distribution, identifying node failures, and redirecting requests to operational nodes to maintain service continuity even in the event of a node failure.
Redis vs Memcached: Pricing and Scalability
Redis
Because Redis requires a lot of memory, clustering enables horizontal scalability, which distributes the load over several instances with smaller memory footprints instead of a single instance with a large memory footprint. In a conventional server application instance, you may use vertical scaling to increase the system resources to improve the program’s performance.
Eventually, the system will be constrained by the availability of technologies to expand the server’s size or—more likely—the fact that increasing the machine’s resources will no longer be cost-effective.
Redis uses technologies like sharding and partitioning to achieve scalability. Redis can extend horizontally to meet growing demand and offer fault tolerance by spreading data among several nodes. Furthermore, automated scaling features are a common feature of managed Redis systems, allowing easy adjustments to meet shifting demands.
Memcached
Memcached is very easy to start up and scale horizontally because of its simplicity and ease of usage. It’s crucial to remember that Memcached lacks built-in data sharding and partitioning features, so developers must manage these aspects manually, which can be difficult as the system grows.
Redis vs Memcached: Multithreading
Redis
What differences in Multithreading take place in the Redis vs Memcached argument? Let’s go through it. Redis is mostly a single-threaded server, meaning a single process handles all instructions and operations. But Redis uses non-blocking I/O and an event-driven paradigm to manage several client connections simultaneously.
This design decision guarantees atomic operations and streamlines implementation. Redis is a single-threaded program, but it can use parallelism if it runs multiple instances—each addressing a separate set of clients—on a single system.
Memcached
In the past, Memcached outperformed Redis in terms of multithreading speed. This implied that Memcached might beat Redis under specific circumstances.
Memcached was renowned in the past for its adequate multithreading support. Because of its multithreaded architecture, it could process several queries at once. Because each incoming request could be handled independently by a different thread, Memcached achieved remarkable performance while dealing with large concurrency.
Memcached was advantageous because of its multithreading capability, particularly when multiple clients needed to access the cache simultaneously.

Credits: Freepik
Redis vs Memcached: Ease of Use
Redis
The most crucial point for any organization is ease of use. We will discuss the user-friendliness parameter in the Redis vs Memcached debate.
Earlier iterations of Redis ran as a single-threaded server. Although this design option guaranteed simplicity and manageability, it was not very effective in processing multiple requests simultaneously.
In Redis, commands were carried out one after the other sequentially. Redis performed exceptionally well in terms of atomic operations and minimal latency. Still, because it was only single-threaded, it may create a bottleneck when there were a lot of concurrent connections.
Redis can be used with any kind of data model because it is a multi-model database. Redis makes writing code easier by streamlining intricate operations.
Memcached
On Memcached, a comparable task is not feasible. However, other approaches will need more lines of code to accomplish the same goals.
Conversely, Memcached only keeps plain text values. Therefore, it is up to the application to handle the complexity of the data structure.
Redis vs Memcached: Supported Languages
Redis
Redis vs Memcached. Let’s begin the section on its supported Languages.
Redis is a flexible option for developers because it offers official clients for many programming languages. Among the languages that are officially supported are:
- Java
- Python
- js (JavaScript)
- Ruby
- C# (.NET)
- Go
- PHP
- C
- C++
- Objective-C
- Swift
Memcached
Like Redis, Memcached has official and third-party clients that support a wide range of programming languages. Among the languages that official clients frequently support are:
- Java
- Python
- PHP
- Perl
- Ruby
- C# (.NET)
- Go
- js (JavaScript)
- C/C++
Redis vs Memcached: Data partitioning
Redis
Redis partitions data using a technique called sharding. Redis uses a notion known as hash slots to divide data among several nodes. Every node in the Redis cluster is responsible for a portion of the fixed number of hash slots—typically 16384—that comprise the critical space.
Redis utilizes a hash algorithm to identify the hash slot that a key belongs to when it is stored or read. This guarantees that the cluster’s keys are distributed equally.
This guarantees that the cluster’s keys are distributed equally. Each Redis cluster node manages a variety of hash slots, and clients can establish connections with any node to carry out tasks. With this method, Redis can grow horizontally by adding or deleting nodes without impacting the dataset as a whole.
Memcached
Memcached uses a less complex data partitioning technique called “consistent hashing.” In this technique, every piece of data is assigned a unique hash value, and every server in the Memcached cluster is assigned a range of hash values.
This makes it possible for the data to be distributed among the servers evenly. A client hashes the key to identify which cluster server is in charge of that key when it wishes to store or retrieve data. When nodes are added or withdrawn, consistent hashing helps keep the balance and reduces the need for data reorganization.
Redis vs Memcached: Transactions
Redis
Redis uses the MULTI, EXEC, and DISCARD commands to support transactions. In Redis, a transaction is a sequence of commands carried out atomically and sequentially. A transaction starts with the MULTI command, and when the EXEC command is sent, all subsequent commands are queued up to be executed atomically.
The DISCARD command is used if a transaction is discarded before execution. Redis transactions offer a mechanism to combine several commands into a single work unit, guaranteeing that either every command in the transaction is carried out or none of it is.
Memcached
Transactions are not natively supported by Memcached by design. Memcached has a straightforward key-value store architecture in which every transaction is stand-alone. While Memcached does not have built-in support for transactions, developers can incorporate custom logic into their applications to achieve atomicity for multiple processes.
When transactions are not as crucial as in databases, Memcached is frequently utilized for caching purposes.
Redis vs Memcached: Geospatial support
Redis
With its Geospatial Indexing features, Redis boasts native support for geospatial data and offers an extensive command set that makes storing, retrieving, and analyzing location-based data using geographic coordinates easier. Using the base command GEOADD, users can easily add one or more geographic objects with their coordinates to a key assigned inside the Redis database.
The GEODIST function is handy for exact distance measurements because it makes it possible to determine the distance between two geographical objects.
Memcached
Memcached does not natively support geospatial data. Memcached lacks specific commands for managing geographic data and is primarily intended as a distributed key-value pair caching system.
Developers will typically need to design proprietary logic in the application layer or consider employing a dedicated geospatial database or other tools if geographic features are needed.
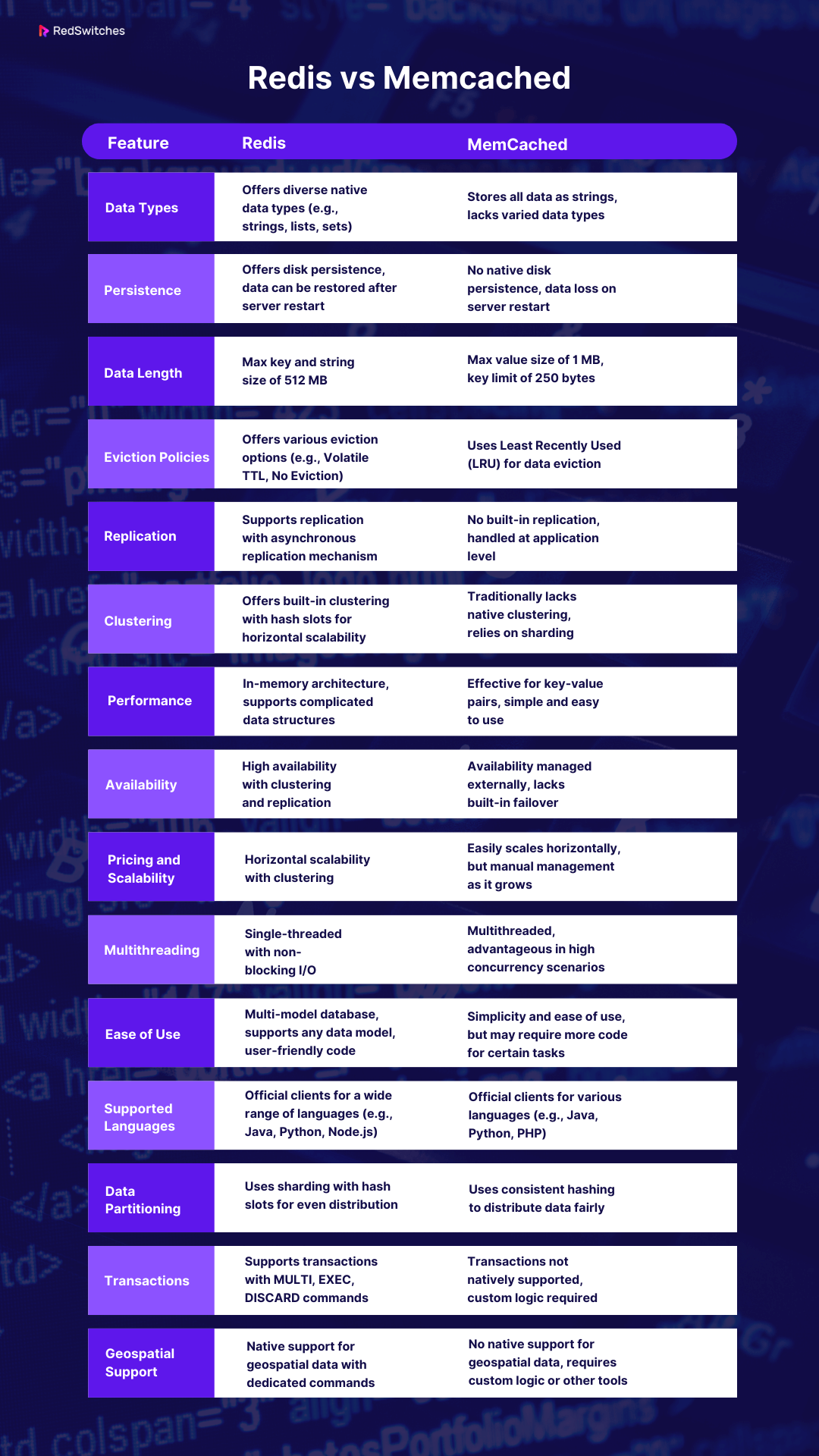
Here’s a quick recap of all the differences discussed above:
When to Use Memcached?
By design, Memcached is incredibly easy to configure and utilize. Memcached might be the best option if your application simply needed basic string interpretation and ran on a few servers.
- Use Memcached when your application involves frequent and repetitive database queries.
- Employ Memcached in distributed environments where scalability is a priority.
When to Use Redis?
Redis is a well-developed, mature product that is still actively being developed. It offers many features and the potential to grow in the future. Redis should be used when:
- You require the ability to deal with data streams and access a larger range of data structures.
- It is necessary to be able to alter and replace the keys and values that are in place.
- Implementing custom data eviction policies (e.g., keeping keys with a longer Time to Live even when the system is out of memory) is necessary.
Conclusion
To sum up, the debate of Redis vs Memcached sheds light on the wide range of caching options accessible to developers. We examined the definitions, benefits, and drawbacks of Redis and Memcached to comprehend their distinct advantages and disadvantages.
Redis distinguishes itself by its variety and scaling possibilities, whereas Memcached thrives in simplicity and fundamental use cases. The decision between them depends on the particular requirements of your project, striking a balance between ease of use and potential expansion.
When making this critical decision, it’s crucial to consider your application’s complexity, scalability needs, and simplicity. In the realm of caching, Redis and Memcached both play essential roles while serving distinct purposes.
RedSwitches is a solid platform for customized hosting solutions that meet the needs of Redis or Memcached. Our knowledge guarantees a smooth connection, enabling developers to maximize the benefits of these potent caching solutions.
FAQs
Q. What is the difference between Memcache and Redis?
While Redis is a flexible, sophisticated key-value store that supports many data formats and capabilities, Memcache is a straightforward, high-performance distributed memory caching technology.
Q. What is the difference between Memcached and Redis medium?
Redis is a more feature-rich and adaptable solution that offers a greater variety of data structures and additional features. In contrast, Memcached best suits basic caching needs and straightforward applications.
Q. Is Redis good for caching?
Redis’s high performance, adaptability, and support for intricate data structures make it a great choice for caching.
Q. In what situations are Memcached and Redis used?
Redis is better suited for complicated applications requiring sophisticated data structures, real-time analytics, and message brokering, while Memcached is best for straightforward applications demanding quick, basic caching.
Q. Is it possible to combine Redis and Memcached in the same application?
Indeed, Redis and Memcached work well together in a hybrid caching architecture. Redis can support more complicated data structures and computations, offering a customized caching solution for a range of application demands. Memcached can handle simple, often accessed data.
Q. What is Memcached and Redis?
Memcached and Redis are both popular open-source, high-performance, in-memory data stores used as caching solutions in 2024. They are utilized to improve the speed and scalability of web applications by reducing the load on databases.
Q. What is the difference between Redis and Memcached?
Redis and Memcached are different in several aspects. Redis supports more advanced data structures, has various Lua scripting capabilities, and offers high availability with Redis Cluster. On the other hand, Memcached is multithreaded and primarily uses simple key-value data storage.
Q. How does Redis handle data storage?
Redis implements advanced data structures such as strings, hashes, lists, sets, and sorted sets to store and manage data efficiently. It also supports transactions and offers Lua scripting capabilities for complex operations.
Q. Why should I consider using Redis over Memcached?
In 2024, Redis is considered superior for various reasons such as its support for advanced data structures, transaction support, Lua scripting, and high availability with Redis Cluster, making it a suitable choice for applications that require these features.
Q. Can Redis be used in AWS Elasticache?
Yes, Redis can be used as a caching engine in AWS Elasticache to enhance the performance of applications deployed on Amazon Web Services (AWS) cloud infrastructure.
Q. What are the benefits of using Memcached over Redis?
Memcached is known for its simplicity and the capability to handle high-throughput, low-latency use cases. It is designed to efficiently store and retrieve simple key-value data while being multithreaded for concurrent access.
Q. How can Redis ensure high availability?
Redis offers high availability through Redis Cluster, which allows automatic partitioning of data across multiple nodes, ensuring fault tolerance and maintaining data availability even in the event of node failures.
Q. Is Redis faster than Memcached?
In certain scenarios, Redis is known to be faster than Memcached due to its efficient handling of data structures, support for Lua scripting, and the ability to perform more complex operations with minimal latency.
Q. Can Redis be used for caching data?
Yes, Redis can be used as a highly effective caching solution for applications, utilizing its in-memory data storage capabilities and fast access to stored data, making it a popular choice for caching purposes.
Q. How does Memcached differ from Redis in terms of data storage?
Memcached uses a simple key-value storage model, while Redis provides support for complex data types like hashes, lists, sets, and sorted sets. This gives Redis an advantage in managing and organizing data in a more structured manner.
