Have you ever wondered how some databases can process data at lightning-fast speeds? The answer is that they use in-memory databases.
To understand how these databases work, you must contrast their functionality with how traditional databases store data on disks. Disk storage slows down data retrieval and processing because of the limitations imposed by the disk hardware. In-memory databases, on the other hand, store data in the computer’s main memory, allowing for much faster access and analysis.
As you can imagine, in-memory databases have revolutionized managing and analyzing data, enabling real-time processing and decision-making.
This article will explore the concept of in-memory databases, their advantages, and their applications in various industries. We’ll discuss how these databases work and how they can benefit your business.
Table Of Contents
- What is an In-Memory Database?
- The Risks Associated With In-memory Databases
- Popular In-Memory Database Solutions
- Use Cases and Applications of In-memory Databases
- In-Memory Databases – Advantages and Disadvantages
- Best Practices and Considerations for In-Memory Databases
- Conclusion
- FAQs
What is an In-Memory Database?
In a conventional database, the data is kept on disk. During the processing of requests, this data is called into the RAM, or local system memory, when required, and the CPU processes as needed. Bottlenecks in this process typically happen because seeking data stored on disks takes time.
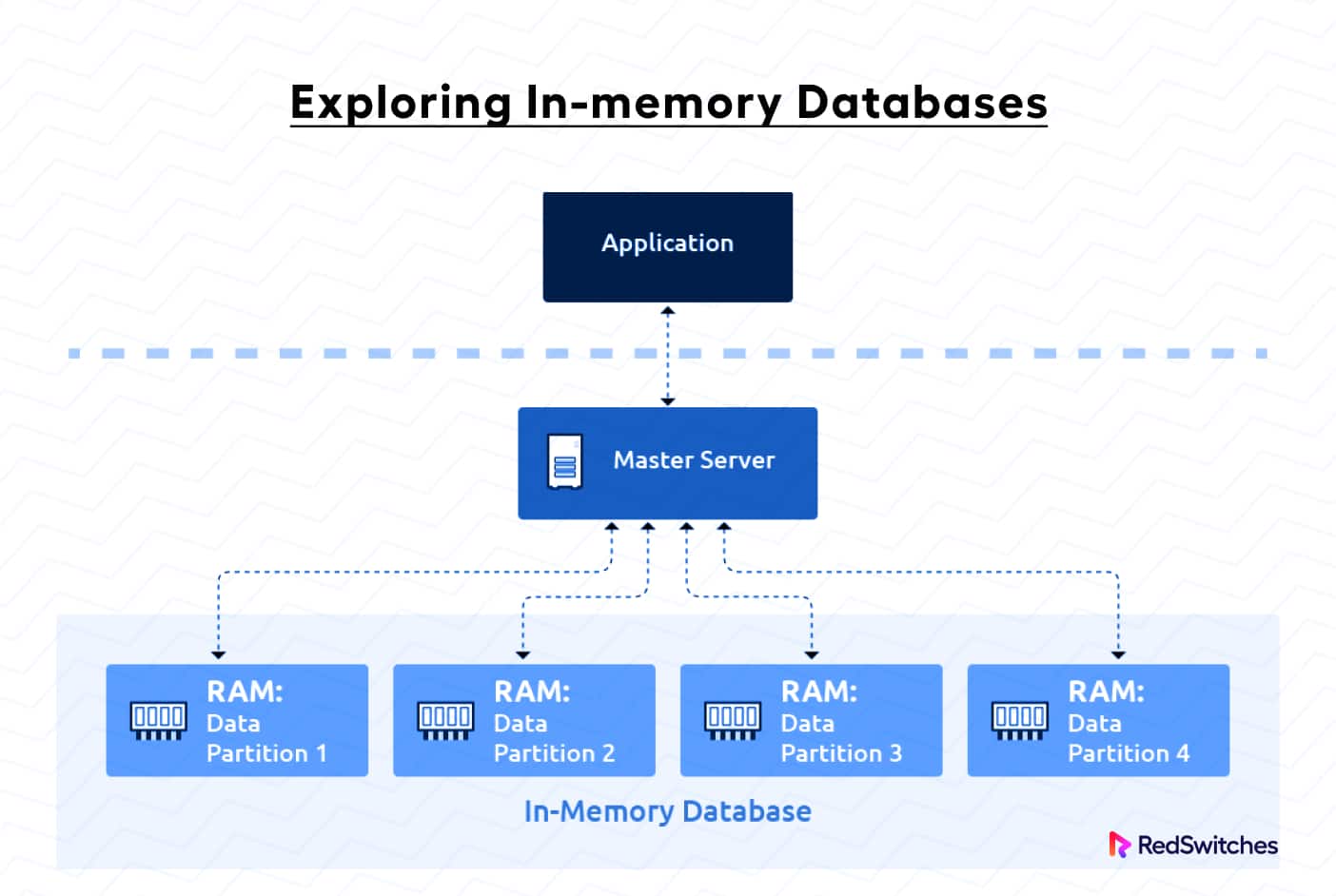
Unlike traditional database management systems, an in memory db primarily stores data in a computer’s main memory (RAM) instead of relying on conventional disk storage. This arrangement facilitates faster data access and retrieval since the data remains instantly available in memory.
These databases are frequently used in applications that carry out real-time data processing and analysis (typical examples are high-frequency trading, real-time analytics, and online gaming).
The Risks Associated With In-memory Databases
Eliminating the constant need to read and write data from the disk in memory db boosts application performance and responsiveness. Nevertheless, they do have limitations. For instance, the volume of data stored in memory is generally restricted, making in-memory databases better suited to use cases where the application would process a small dataset much faster.
Despite providing rapid access, in-memory db has a much higher risk of data loss in the event of a server failure. Since there is no data persistence, system failure results in losing everything in the memory.
Additionally, the cost of system memory is higher than disk storage. So, if you wish to process a large dataset through an in-memory db, you’ll have to invest in expensive system memory.
As a result, opting for an in memory database is a choice dictated by specific use cases. These databases are great for high-speed access to low volumes of data where a significant degree of data loss is acceptable. For example, a large eCommerce website can keep product information in persistent storage on disk but use an in memory db for the shopping cart for a smoother user experience.
Popular In-Memory Database Solutions
In-memory databases have gained much popularity in recent years due to their ability to provide fast data access and processing. Some popular in-memory database solutions that businesses can use for their projects are listed below:
Redis
Redis stands for Remote Dictionary Server. It’s an open-source, in-memory data structure that fits various applications, such as an application database, a cache, or a message broker system. Developers use Redis to implement data structures such as strings, hashes, lists, and sorted sets. In addition, the applications benefit from its persistence and high-level atomic operations.
Memcached
It is a highly efficient, open-source system for distributed memory object caching. Storing data and objects in RAM enhances application performance by minimizing the frequency at which it reads and writes to external data sources, such as databases or APIs. It’s beneficial for increasing the speed of dynamic web applications by caching queries, results, API calls, and page rendering data.
Apache Ignite
Apache Ignite is a distributed platform that seamlessly handles databases, caching, and data processing. It is equally great for transactional, analytical, and streaming workloads while delivering impressive in-memory performance on a huge (petabyte) scale. It integrates well with other Apache products, such as Hadoop and Spark, and can run SQL queries supporting joins and secondary indexes.
SAP HANA
SAP HANA (High-Performance Analytic Appliance) is a unique software solution developed by the German corporation SAP SE. As an in-memory column-oriented relational database management system, it employs an in-memory computing engine to increase data processing speeds. This allows HANA to process data stored in RAM instead of continuously accessing data on the disk. As a result, HANA offers much faster query processing than traditional databases.
VoltDB
VoltDB is an in-memory SQL database purpose-built to power real-time applications. VoltDB provides ACID-compliant transactional consistency at scale, a rare database feature. Its architecture allows for real-time in-memory analytics, a valuable feature for financial, telecommunications, and gaming applications requiring quick decision-making.
Oracle TimesTen
The Oracle TimesTen In-Memory Database is a comprehensive relational database system optimized explicitly for in-memory operations, offering both data persistence and recoverability features. It’s designed to run in the application tier and deliver rapid, simple, and local data operations. Holding the entire database in memory offers low response times and high throughput for online transaction processing (OLTP) workloads.
SQLite
By default, SQLite operates as an embedded database that stores data on disk in a single file. However, it also allows you to move the database to memory. In this scenario, all the data is stored in RAM instead of the file on disk.
To use SQLite as a in memory db, you must open a database connection with a unique name: “:memory:”
For example, in Python, you can use the following code to create an in memory db:
import sqlite3
# Connect to an in-memory database
connection = sqlite3.connect(':memory:')
MongoDB In-Memory Storage Engine
MongoDB, a popular NoSQL database, also provides an in-memory storage engine. This feature is available only in MongoDB Enterprise Edition and MongoDB Atlas. It’s crucial to note that this in-memory option doesn’t replace MongoDB’s default disk-based storage engine (WiredTiger) but instead provides an alternative for specific use cases.
MongoDB’s in-memory option maintains transactional guarantees, including consistency and durability. The downside is that when an instance using the in-memory storage engine shuts down or is terminated, all data is lost from the in-memory storage engine. As a result, MongoDB’s in-memory storage engine is often used for caching, real-time analytics, and processing transient data.
Java In-Memory Databases
Java offers several in-memory database options to simplify the development process, speed up data retrieval and manipulation, and allow the applications to work with live data in real time.
Here are a few popular Java In-Memory Databases you might find helpful:
- H2 Database Engine
- Multi-faceted: Able to handle several connections, tables, and schemas simultaneously.
- Diverse Modes: Operate in embedded or server modes and support in memory db.
- Accessible Interface: Comes with a browser-based console application for ease of use.
- Derby
- Compact Size: The basic engine and the embedded JDBC driver only occupy approximately 2.6 MB.
- Embedded JDBC Driver: Derby has an incorporated JDBC driver that developers use to integrate into Java apps.
- HyperSQL
- Hazelcast
H2 is a lightweight Java-based SQL database that supports standard SQL and JDBC API. Thanks to the versatile nature of this system, developers integrate it with Java applications or operate in a client-server configuration.
Critical features include:
Derby, also called Java DB, is a comprehensive and open-source RDBMS (Relational Database Management System) built upon Java and SQL.
Notable features include:
HyperSQL, like H2, is a relational database engine written in Java. It offers a small, fast database engine that offers both in-memory and disk-based tables.
It can be run in the embedded or server mode and fully supports SQL-92, SQL-99, and SQL:2008 standards.
Hazelcast is an open-source in-memory data grid based on Java. It mainly provides distributed storage and computation services for all applications. Popular features include in-memory storage capabilities, horizontal and vertical scaling options, and distributed computing capabilities.
Use Cases and Applications of In-memory Databases
In-memory databases can deliver performance up to millions of transactions per second with sub-millisecond response times. That’s why they are used when high-speed data access, data volume, and real-time analytics are crucial operational requirements.
Here are some scenarios where in memory db are critical application components:
Real-Time Analytics
Real-time analytics is critical for many industries, such as healthcare, finance, and telecommunications. These databases can quickly process vast volumes of data expected in real-time analytic processing. This allows users to extract insights quickly and make better decisions.
Caching
In-memory db are frequently used as caching systems since they provide low-latency access to critical data. This benefits web-based applications or services requiring quick data retrieval to ensure smooth user experiences.
Session Stores
Web applications often need to store session data. In-memory databases can store this data with high fidelity and ensure high-speed access and horizontal scalability. As a result, web applications can deliver smooth performance and user experience.
High-Speed Transactions
Industries like financial services need to process high volumes of transactions quickly. With their high-speed data access, in-memory databases can effectively support such high-speed transactions.
Gaming Platforms
In the gaming industry, in-memory databases implement leaderboards, multiplayer matchmaking, and game state data. Their high-speed response time makes them ideal for real-time gaming applications.
Telecommunications
In the telecom industry, in memory db process Call Detail Records (CDRs) in real-time support high-speed billing operations, network event processing, and real-time analytics.
Internet of Things (IoT)
Given their superior speed and performance, in-memory databases can collect, process, and analyze huge volumes of data generated by IoT devices in real time.
Risk Management and Fraud Detection
In-memory databases can process and analyze huge datasets in real time, enabling immediate detection and early action for real-time risk management and fraud detection in financial services or online businesses.
Despite the apparent benefits of in memory db, there are considerations like cost (RAM is more expensive than disk storage) and data volatility (risk of data loss on power failure unless backed by persistent storage).
In-Memory Databases – Advantages and Disadvantages
In-memory databases have their unique advantages and disadvantages.
Here’s what you should know:
Advantages
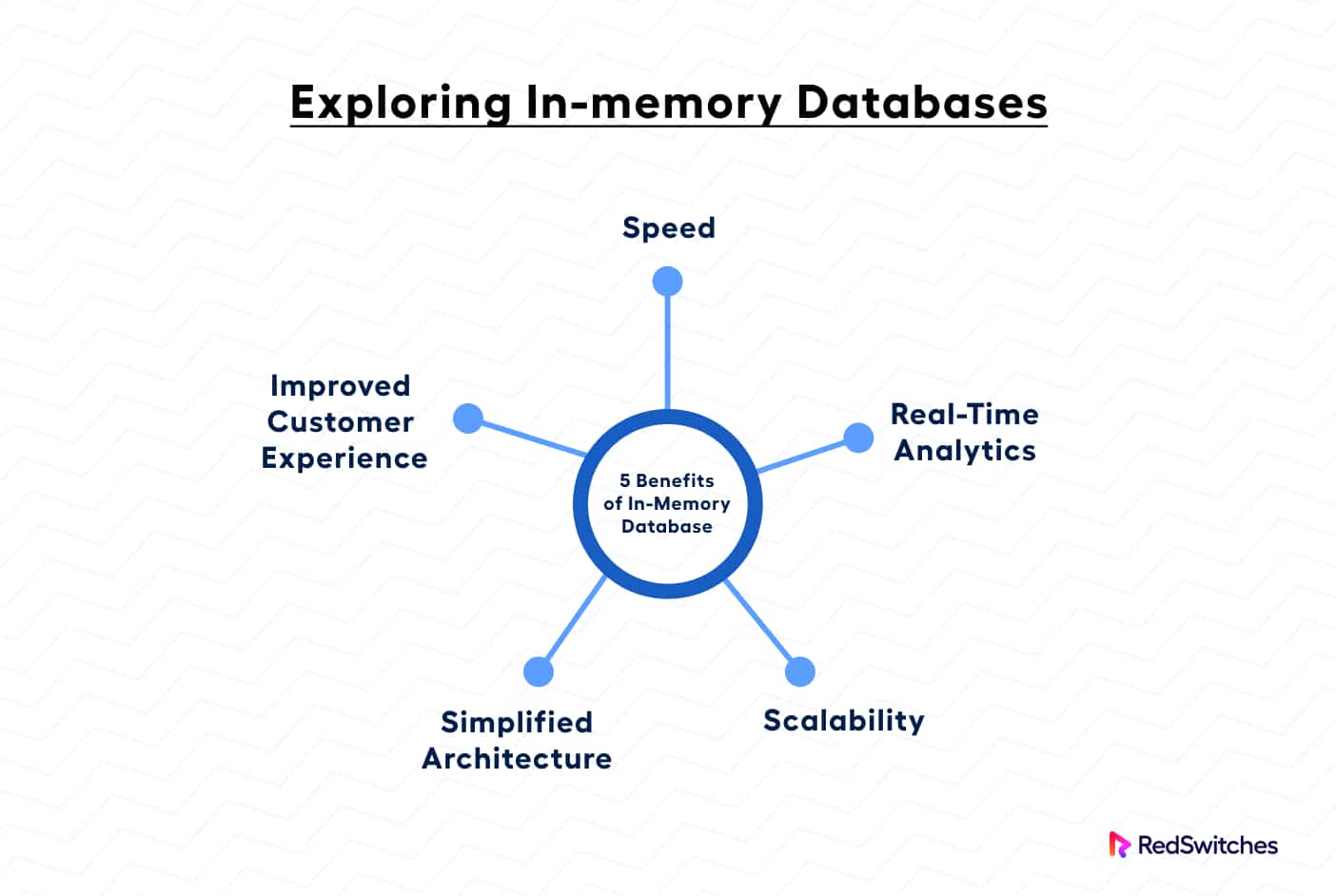
In memory, db offers the following advantages:
1. Speed
The enhanced speed is the most noticeable benefit of using an in memory db. Unlike traditional disk storage, data access times can be significantly faster when stored in memory.
2. Real-time Analytics
An in memory db enables real-time analytics, providing instant insights that help in operational and analytical decision-making.
3. Scalability
Many in memory db offer horizontal scalability, which allows the projects to easily handle additional data loads by distributing data and processing requirements across multiple servers.
4. Simplified Architecture
Since all data resides in memory, applications don’t have to perform some traditional database management transactions. This simplifies the database architecture and reduces the overhead costs.
5. Improved Customer Experience
An in memory db can significantly improve the customer experience of applications through faster responses and lower latency.
Disadvantages
Despite the above advantages, in-memory databases can offer the following challenges.
1. Cost
RAM is significantly more expensive than traditional disk storage. Depending on the size of the database, costs of operating an in memory db can rack up quickly.
2. Volatility
One of the main drawbacks of these databases is memory volatility. In a power failure or system crash, all data stored in memory can be lost if not persistently backed up.
3. Storage Limitation
The size of an in memory db is limited by the amount of memory available, which might not be ideal for more extensive databases.
4. Required Systems Redesign
Implementing an in memory db system might require a redesign of the whole system architecture to accommodate the new technology and reap its benefits.
Best Practices and Considerations for In-Memory Databases
Implementing an in-memory database can significantly improve the performance and speed of data processing. However, following some best practices and considerations before working with an in memory db can help you avoid the pitfalls.
In-Memory Best Practices
- Use Hybrid Durability Modes
Implement a strategy that combines the benefits of both in-memory and persistent databases. Despite the speed an in-memory db provides, it’s still important to persist essential information on a disk for durability.
- Understand Your Workload
Evaluate what suits your needs best. An in-memory store may not be suitable for applications with extensive data storage needs but only requires moderate to low-speed data access.
- Regularly Back up
Though in-memory databases are faster, they are also volatile. A power disruption can lead to data loss. Implementing a regular backup routine can help you avoid losing data.
- Data Partitioning
In-memory databases can distribute data across many servers. However, it’s important to partition your data such that commonly accessed data should reside together (ideally on the same server).
- Prioritize Security
In-memory databases can contain valuable data. Ensure data is secure by utilizing proper encryption and access control methods.
Considerations
- Size of the Database
The size of an in-memory database is directly proportional to the cost, as memory is expensive. If the database is large, the cost might be a significant factor in adopting these databases.
- Data Persistence
In-memory databases store data in RAM, and any disruption can result in data loss unless it’s regularly backed up or persisted in non-volatile storage.
- The Nature of the Data
Highly sensitive data may only be suitable for specific in-memory db if it can ensure adequate security measures.
- Vendor Support
When choosing an in-memory db, consider the vendor’s level of support. Good support can help you tackle issues and efficiently maintain your database.
- Hardware Dependency
The performance of an in-memory database largely depends on the hardware. As a result, an in-memory db should always be paired with efficient hardware for optimum performance.
Conclusion
In-memory databases offer a revolutionary approach to data management with their breakneck processing speed and real-time analytics capabilities. They can significantly increase performance across various sectors, including finance, telecommunication, gaming, and IoT.
However, successfully implementing and integrating these databases requires careful planning, understanding the workload requirements, and stringent security measures. With RedSwitches, a premier hosting provider known for powerful, reliable bare metal servers, you can seamlessly integrate in-memory databases into your infrastructure to maximize application potential.
Visit RedSwitches today and explore their hosting solutions to meet your in-memory database needs. Your next data-driven breakthrough with in-memory databases is a click away.
FAQs
Q: Where are in-memory databases commonly used?
A: In memory, db are commonly used in real-time analytics applications, high-speed transactions, caching, session storage, gaming leaderboards, IoT data processing, and other use cases that require rapid access to data.
Q: How are in-memory databases different from traditional databases?
A: Traditional databases store data on disk, resulting in longer access times due to disk I/O delays. On the other hand, in memory, db stores data in RAM, which, being faster memory, substantially reduces the time needed for data access and manipulation.
Q: Are in-memory databases expensive?
A: While storing data in memory can be more expensive than storing data on a disk due to the higher cost of RAM, the tremendous performance boost can justify the cost for applications requiring real-time or near-instantaneous responsiveness.
Q: Is data stored in an in-memory database persistent?
A: By default, data in an in-memory database is volatile and is lost when the system shuts down or crashes. However, many in-memory databases offer persistence options, usually by saving the data to disk at regular intervals or upon specific triggers.
Q: What type of applications benefit most from an in-memory database?
A: Applications that require real-time analytics, high-speed transactions, caching, and large-scale session storage tend to benefit the most from in-memory databases due to their need for rapid data access and manipulation.
Q: How does a hosting provider like RedSwitches help with in-memory databases?
A: A hosting provider like RedSwitches offers reliable, high-performance servers critical for the smooth operation of in-memory databases. They provide the necessary infrastructural support and ensure the optimum performance of your in memory db, enabling you to explore the power of real-time data processing.
