
In the ever-evolving data science landscape, two titans have consistently stood out in the Python ecosystem: Pandas vs NumPy. These libraries are cornerstones in any data scientist’s toolkit, each with unique strengths. But what is the difference between Numpy and Pandas? When should one be favored over the other?
As we delve into the nuances of these two libraries, it’s essential to understand the context in which they operate. Data science, as a field, has seen exponential growth. According to the U.S. Bureau of Labor Statistics, the demand for data science skills is expected to grow significantly, with a projection of a 15% increase in data science jobs from 2019 to 2029, much faster than the average for all occupations.
This growth is mirrored in the increasing amount of data generated and processed. IDC’s “Data Age 2025” report predicts that the global data sphere will grow to 175 zettabytes by 2025. Amidst this data deluge, tools like Pandas and NumPy are both conveniences and necessities.
Let’s dive into the world of arrays and data frames and unravel the distinct characteristics that make Pandas vs NumPy indispensable and distinct in data science.
Table Of Contents
- What is Pandas?
- What is NumPy?
- Pandas Vs NumPy: 11 Key Differences
- Pandas Examples: Simplified for Easy Understanding
- NumPy Examples: Practical and User-Friendly
- Conclusion
- FAQs
What is Pandas?
Pandas is a data science and analytics powerhouse known for its comprehensive data manipulation capabilities. Born out of the need for a more flexible and intuitive tool for data analysis in Python, Pandas has rapidly become a staple in the data science community. It’s a high-level library that provides robust, easy-to-use data structures and data analysis tools.
Key Features of Pandas
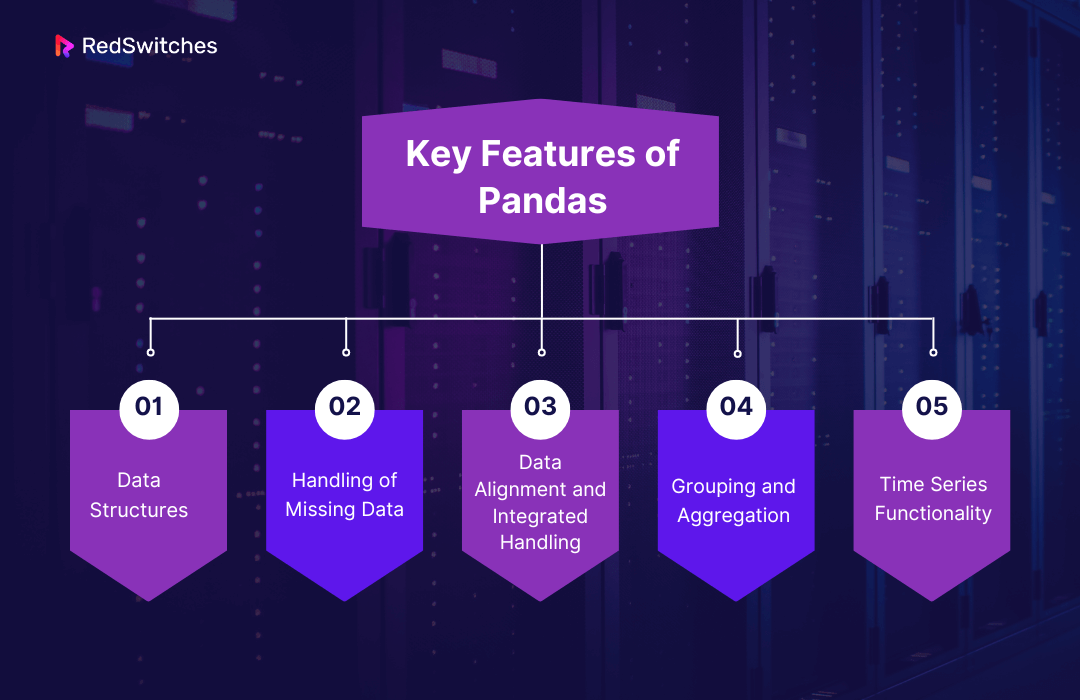
- Data Structures: Pandas introduces two primary data structures: Series (one-dimensional) and DataFrame (two-dimensional). These structures are built on top of NumPy arrays, offering a rich set of functions for fast data manipulation.
- Handling of Missing Data: One of the more tedious tasks in data analysis, the handling of missing data, is streamlined in Pandas. It offers multiple ways to detect, remove, and replace missing values in datasets.
- Data Alignment and Integrated Handling: Pandas automatically aligns data for operations involving multiple data structures and seamlessly handles heterogeneous data types within a DataFrame.
- Grouping and Aggregation: With its powerful ‘groupby’ functionality, Pandas enables complex data aggregation operations, making it easy to perform multi-level grouping and provide summary statistics.
- Time Series Functionality: Pandas excels in time-series data manipulation, offering extensive capabilities for date range generation, frequency conversion, moving window statistics, and date shifting.
Pros And Cons of Pandas

Pros:
- Ease of Use: Pandas are designed with simplicity, making data manipulation and analysis more intuitive and accessible.
- Rich Functionality: It offers many functionalities, covering most use cases in data preprocessing, exploration, and analysis.
- Strong Community Support: Being a popular library, Pandas has a robust community, ensuring continuous development and abundant resources for learning and troubleshooting.
Cons:
- Performance Issues with Large Datasets: While Pandas is efficient with medium-sized data, it can struggle with large datasets, particularly those that don’t fit into memory.
- Learning Curve: Beginners might initially find Pandas’ breadth of functionalities overwhelming.
- Limited Support for 3D Data: Pandas primarily handles 1D and 2D data, with limited support for three-dimensional data, which might require additional tools like xarray.
In conclusion, Pandas is a comprehensive data manipulation and analysis tool particularly suited for structured data. Its user-friendly nature and extensive capabilities make it an invaluable asset in the data scientist’s toolkit.
Also Read: Data Warehouse and Data Mining: 12 Things To Know

Credits: Freepik
What is NumPy?
NumPy, short for Numerical Python, is a fundamental package for scientific computing in Python. It forms the backbone of many Python-based data science and scientific computing tools. NumPy is celebrated for its powerful N-dimensional array object, broadcasting, and comprehensive mathematical functions. It’s the go-to library for numerical operations in Python, providing a high-performance multidimensional array object and tools for working with these arrays.
Key Features of NumPy
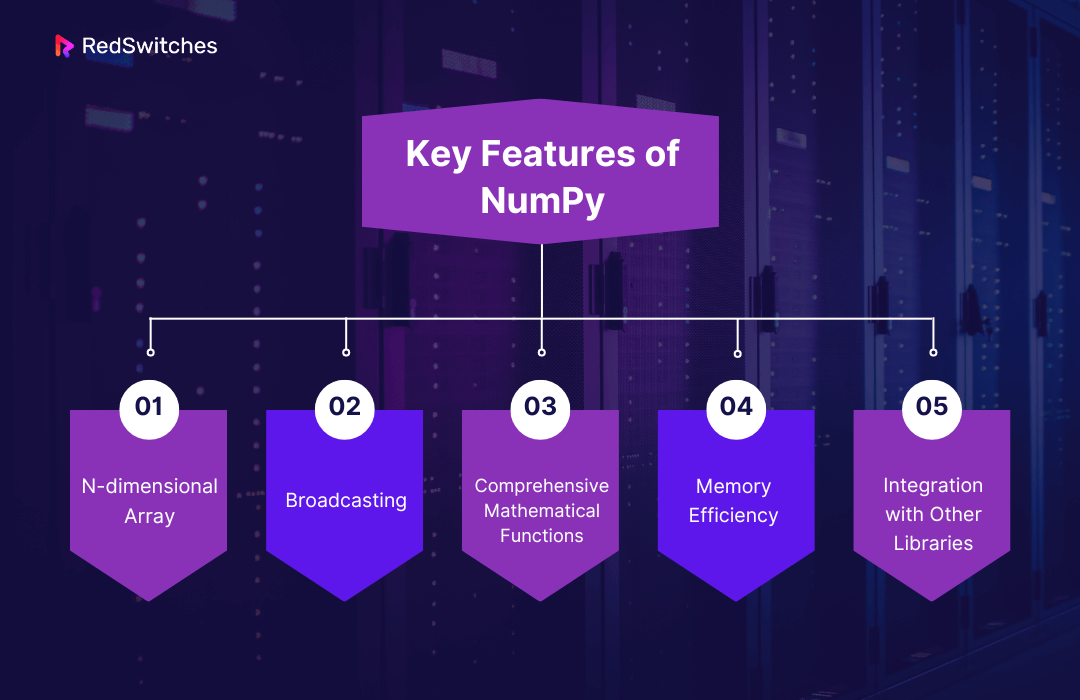
- N-dimensional Array: NumPy’s main object is the homogeneous multidimensional array. It’s a table of elements, usually numbers, all of the same type, indexed by a tuple of positive integers.
- Broadcasting: A powerful mechanism that allows NumPy to work with arrays of different shapes when performing arithmetic operations.
- Comprehensive Mathematical Functions: NumPy provides a vast collection of mathematical functions like linear algebra operations, Fourier transforms, and random number generation, which operate on these arrays.
- Memory Efficiency: NumPy arrays are more memory-efficient and optimized for performance than Python lists, especially for large data sets.
- Integration with Other Libraries: NumPy forms the foundation of many other libraries like Pandas, SciPy, Matplotlib, scikit-learn, etc., enabling various computations and data manipulations.
Also Read Network Databases: Cheat Codes You Must Know
Pros And Cons of NumPy

Pros:
- High Performance: NumPy arrays are stored at one continuous place in memory, making the processing fast.
- Extensive Mathematical Functions: It provides numerous mathematical operations, making complex numerical computations straightforward.
- Interoperability: Can be easily integrated with a wide range of databases and data formats.
Cons:
- Less Flexible: NumPy arrays have a fixed size and require the same data type, making them less flexible than Pandas DataFrames.
- Memory Consumption: NumPy can consume significant memory for very large arrays.
- Steep Learning Curve for Beginners: The array-based approach of NumPy might be overwhelming for beginners, especially those unfamiliar with vectorized operations.
NumPy stands as a pillar in the realm of numerical computing in Python. It’s efficiency and high performance make it an indispensable tool for tasks involving numerical data, mainly when dealing with large arrays or requiring high-speed computations.
Pandas Vs NumPy: 11 Key Differences
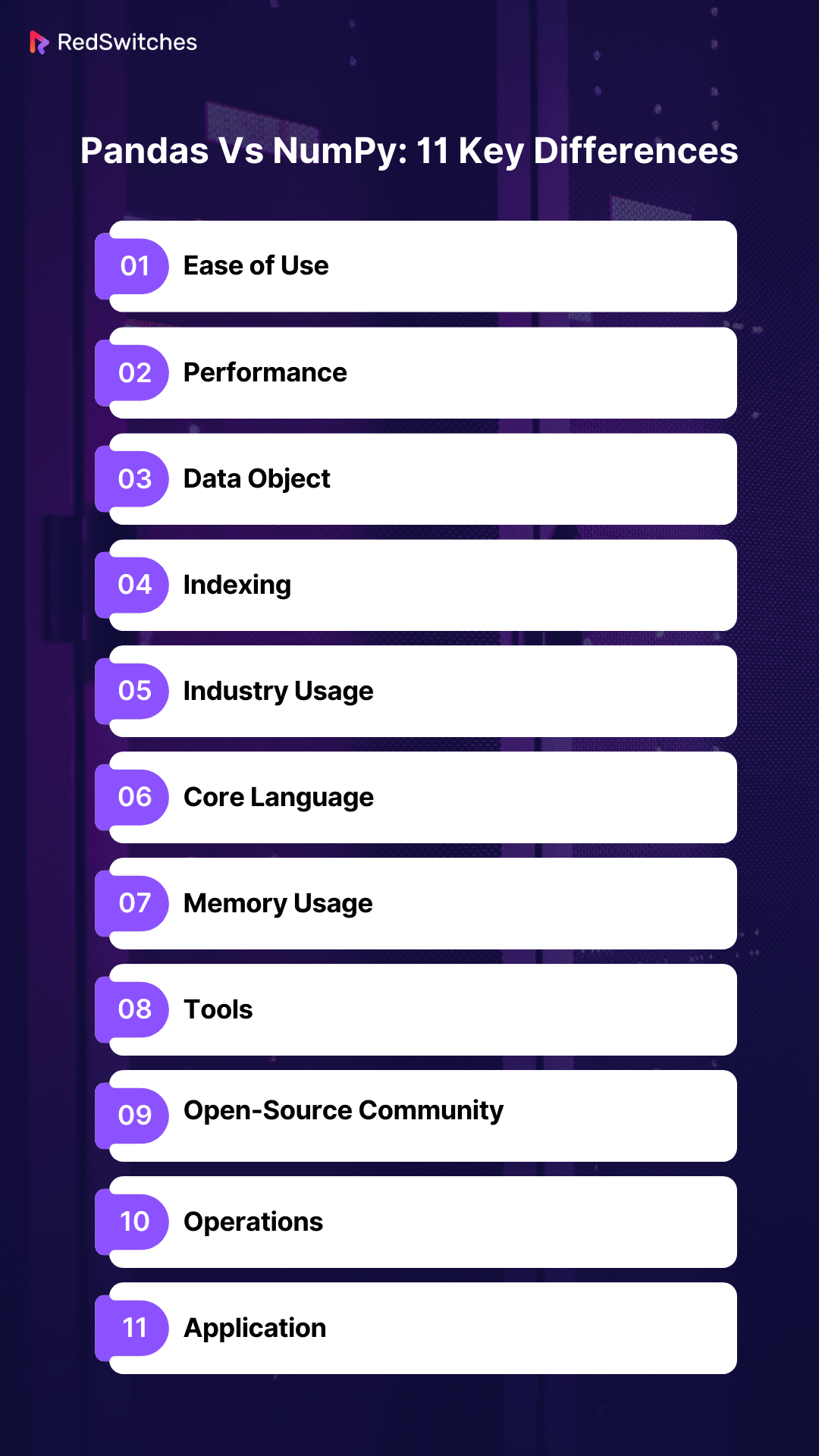
Pandas vs NumPy. Both are powerhouse libraries, each lauded for their respective strengths and functionalities. However, despite their everyday use in data analysis and manipulation, they are distinct in their capabilities, design philosophy, and optimal use cases.
Understanding the differences between Pandas and NumPy is not just an academic exercise; it’s a practical necessity for data scientists and analysts. It’s about choosing the right tool for the right task, about efficiency, and, ultimately, about the effectiveness of your data-driven solutions.
Exploring the Pandas vs NumPy 11 key differences will guide data scientists in navigating their choices.
Let’s dive deep into these differences, unraveling the unique attributes that make each library indispensable in the data science toolkit, and explore how their strengths can be leveraged in various scenarios.
Ease of Use
When it comes to the ease of use of Pandas and NumPy, understanding how they cater to different aspects of data manipulation and analysis is crucial. Their design philosophies and functionalities are tailored to meet specific needs, affecting how user-friendly they are for various tasks.
Pandas: User-Friendly for Data Manipulation
Pandas is often praised for its user-friendly nature, especially when dealing with structured data like CSV files, Excel spreadsheets, or SQL query outputs. Here’s why:
- Intuitive Data Structures: Pandas introduces two main data structures – Series and DataFrame. A Series is a one-dimensional labeled array, while a DataFrame is a two-dimensional labeled structure, where each column can be of a different type. These structures are akin to what people use in spreadsheets, making them intuitive.
- Handling Real-world Data: Pandas is designed to ease the handling of ‘messy’ real-world data. For instance, it effortlessly handles missing values, varying data types, and data coming in different shapes and sizes.
- High-level Data Manipulation Tools: With Pandas, tasks like data filtering, grouping, and aggregation are straightforward. It provides functions that allow you to slice, dice, and summarize your dataset intuitively and concisely.
- Strong IO Capabilities: Pandas offers extensive capabilities to read and write data from and to various file formats, making it extremely user-friendly for data importing/exporting.
Also Read A Short Overview of SQL With Basic Commands
NumPy: Optimized for Numerical Computing
NumPy, while not as intuitive as Pandas for general data manipulation, excels in numerical computations. It’s more specialized, and here’s how it fares in ease of use:
- Array-oriented Computing: NumPy’s central feature is its N-dimensional array object. For those familiar with vectorized operations and linear algebra, NumPy’s approach is straightforward and efficient. However, this might be less intuitive for beginners than Pandas’ spreadsheet-like structures.
- Less Direct Handling of Heterogeneous Data: NumPy arrays are meant for homogeneous numerical data. This focus makes it less versatile and intuitive for handling datasets with multiple data types, as commonly encountered in real-world data.
- Mathematical Operations: NumPy is unbeatable regarding complex mathematical operations. But this also means it’s more oriented towards users comfortable with mathematical concepts and array-based computing.
Pandas is generally more approachable for a layperson or someone new to data science due to its similarity to spreadsheet data structures and its robustness in handling various data types.
While incredibly powerful for numerical computations, NumPy has a steeper learning curve and is more suited for tasks requiring efficient and sophisticated mathematical operations.
Understanding these differences in ease of use can help you decide which library to reach for depending on the task, whether manipulating a complex dataset or performing high-speed numerical computations.
Performance
Performance is critical in data science, especially when working with large datasets or requiring high-speed computations. When comparing Pandas vs NumPy in terms of performance, it’s essential to understand the kinds of tasks each library is optimized for.
Pandas: Performance in Data Manipulation
Pandas is highly efficient for data manipulation tasks, particularly with structured data. Here’s how it stands regarding performance:
- Handling Structured Data: Pandas is optimized for performance in handling structured data. Operations like joining, merging, and pivoting tables are streamlined and relatively fast, even with large datasets.
- Efficiency with Small to Medium-Sized Data: Pandas perform admirably when dealing with small to medium-sized datasets. However, performance can degrade as data size increases, especially datasets that don’t fit into memory.
- Optimized Internally with NumPy: Under the hood, Pandas uses NumPy for numerical computations. This means it can leverage NumPy’s performance advantages for numerical data operations.
NumPy: Optimized for Numerical Computations
NumPy is a performance champion in numerical computations. Here’s why:
- Efficiency with Large Arrays: NumPy’s core functionality revolves around its n-dimensional array. These arrays are more memory-efficient and performant, especially for large datasets and array operations.
- Vectorization: NumPy uses vectorized operations implemented in C, making them very fast compared to traditional looping techniques in Python.
- Lower Memory Footprint: Since NumPy arrays are homogeneous and tightly packed in memory, they have a lower memory footprint than Pandas DataFrames, which can be crucial for performance when handling large data volumes.
The performance of Pandas vs NumPy is context-dependent. For tasks involving complex data manipulations, particularly with structured data, Pandas is the preferred choice. However, when it comes to heavy numerical computations, especially involving large arrays, NumPy is significantly faster and more memory-efficient.
It’s not uncommon for data scientists to use both libraries in tandem, leveraging the strengths of each: Pandas for data wrangling and preprocessing and NumPy for heavy numerical analysis. Understanding this complementary relationship is key to maximizing performance in your data science projects.
Data Object

Credits: Freepik
The fundamental data structures provided by Pandas vs NumPy are central to understanding their capabilities and use in data science. The nature of these data objects significantly influences how data is handled, manipulated, and stored.
Pandas: DataFrame and Series
Pandas provides two main data objects, Series and DataFrame, each designed for ease of use and flexibility.
Series:
- A Series is a one-dimensional labeled array capable of holding any data type (integers, strings, floating-point numbers, Python objects, etc.).
- It’s akin to a column in a spreadsheet or a single vector in a dataset.
- Each element in a Series is assigned a unique label, the index, making data manipulation intuitive and flexible.
DataFrame:
- The DataFrame is a two-dimensional labeled data structure comparable to a table in a relational database, an Excel spreadsheet, or a data frame in R.
- It consists of rows and columns, where each column can be of a different data type.
- DataFrames are ideal for representing real-world data, easily accommodating various types of information.
NumPy: N-dimensional Array
NumPy’s core data object is the n-dimensional array (ndarray), emphasizing numerical computation efficiency.
N-dimensional Array:
- NumPy arrays are grid-like structures where every element is of the same type, typically numerical data, which increases computational efficiency.
- They can have any number of dimensions, allowing for the representation of vectors (1D), matrices (2D), or tensors (higher dimensions).
- Arrays are optimized for vectorized operations, meaning that operations are applied to each element without the need for explicit loops.
The choice between Pandas vs NumPy often comes down to the nature of the data and the specific requirements of the task. With its Series and DataFrame, Pandas is more versatile for handling and analyzing structured data.
In contrast, NumPy’s n-dimensional arrays are unparalleled in efficiency for numerical computations and large data volumes. Understanding these differences in data objects allows data scientists to optimize their workflows and choose the most appropriate tool for their data needs.
Indexing
Indexing is critical to data manipulation, as it dictates how data is accessed, modified, and organized. Pandas and NumPy offer robust indexing capabilities, but their approaches and functionalities differ, influencing how they are used in various data operations.
Pandas: Flexible and Powerful Indexing
Pandas is renowned for its flexible and powerful indexing capabilities, which make data manipulation more intuitive and efficient.
Label-based Indexing:
- Pandas allows for label-based indexing using row and column labels, making data access and manipulation more intuitive.
- The .loc[] method is used for label-based indexing, enhancing readability and ease of use, especially for those familiar with SQL or spreadsheet software.
Hierarchical Indexing:
- Pandas supports hierarchical or multi-level indexing, allowing you to represent data in multiple dimensions in a tabular format.
- This feature helps organize and summarize data in complex datasets.
Handling Time Series Data:
- Pandas excels in handling time series data, offering specialized indexing for date and time.
- This includes capabilities for date range generation, frequency conversion, and moving window statistics.
NumPy: Position-based Indexing
NumPy’s indexing focuses more on array positions, catering to its numerical computing strengths.
Integer-based Indexing:
- NumPy primarily uses integer-based indexing, where you access elements by their position in the array.
- This method is straightforward and efficient but might not be as intuitive as label-based indexing for some users.
Boolean Indexing:
- NumPy also supports Boolean indexing, which is useful for filtering elements based on a condition.
- This can be particularly powerful for numerical computations where conditions are based on array values.
Slicing:
- Both Pandas and NumPy support slicing, but NumPy’s is particularly efficient for subsetting arrays, especially in multi-dimensional arrays.
Pandas vs NumPy indexing capabilities are tailored to their respective strengths: Pandas for flexible and intuitive data manipulation and NumPy for efficient numerical computations.
Understanding these differences in indexing approaches is crucial for data scientists to effectively navigate and manipulate data, whether it involves complex data analysis tasks or high-speed numerical operations.
Industry Usage

Credits: Freepik
The Pandas vs NumPy industry usage varies based on the specific requirements and nature of data tasks within different sectors. Understanding how industries leverage these libraries can provide insight into their practical applications and suitability for various use cases.
Pandas: The Go-To for Data Wrangling and Analysis
Pandas is widely used across industries for data analysis, preprocessing, and wrangling tasks, especially where structured data is involved.
Finance and Banking:
- In finance, Pandas is extensively used for time series analysis, financial modeling, and risk management. Its ability to handle time-stamped data makes it invaluable for trend analysis and forecasting.
Marketing and Sales:
- Pandas aids in customer data analysis, market segmentation, and sales data analysis. Its powerful data manipulation capabilities help derive insights from customer behavior and sales trends.
Healthcare:
- It’s employed for patient data analysis, research data management, and statistical analysis. Pandas’ ability to handle diverse data types is crucial in managing complex healthcare datasets.
NumPy: Essential for Numerical and Scientific Computing
NumPy is fundamental in fields that require heavy numerical computing, especially those involving large datasets and complex mathematical models.
Scientific Research:
- NumPy is a staple in scientific computing for tasks like numerical simulation, statistical modeling, and data analysis in physics, chemistry, and bioinformatics.
Engineering:
- Used extensively in engineering fields, particularly for simulations, signal processing, and image processing, where its array operations and mathematical functions are critical.
- NumPy forms the backbone of many machine learning algorithms, especially in preprocessing steps and operations involving linear algebra.
While there’s a significant overlap in the use of Pandas vs NumPy across various industries, their specific strengths cater to different needs.
Pandas is the preferred choice for data wrangling and analysis in business-centric roles, while NumPy is indispensable in fields requiring intensive numerical computations.
Understanding these industry-specific applications aids in selecting the right tool for the task, ensuring efficiency and effectiveness in data-driven processes.
Also Read A Comprehensive Overview of Big Data Databases
Core Language
Credits: Freepik
Exploring the core language and underlying design principles of Pandas vs NumPy reveals the foundational differences that guide their functionality and usage in data science.
Pandas: Built on Python and NumPy
Pandas is built on top of Python and heavily relies on NumPy for its operations, especially for numerical computations.
Pythonic Nature:
- Pandas is deeply integrated with Python, following its idioms and structures. This makes it highly intuitive for Python users, as it seamlessly aligns with the language’s syntax and paradigms.
- The library’s design and functionality are intended to simplify and streamline data manipulation and analysis tasks in Python, adhering to Python’s philosophy of readability and simplicity.
Integration with NumPy:
- Underneath, Pandas leverages NumPy for numerical operations. This means that it inherits NumPy’s efficiency and speed for array computations.
- The close integration with NumPy ensures that Pandas can handle numerical data with the performance benefits of NumPy’s array processing capabilities.
Also read How to Check Python Version in Linux, Windows, And macOS
NumPy: The Foundation of Python’s Scientific Stack
NumPy, on the other hand, is often considered the foundation of Python’s scientific stack, providing the essential building block for numerical computation.
Optimized for Performance:
- NumPy is written in C and Python, making it highly efficient, especially for array operations and mathematical computations.
- Its core, written in language C, ensures fast execution, which is crucial for handling large arrays and complex mathematical operations.
Array Programming Paradigm:
- NumPy introduces an array programming paradigm into Python, which departs from typical Python lists or data structures. This paradigm is particularly effective for numerical computations and is aligned with mathematical and scientific computing requirements.
- The focus on array operations means that NumPy is more specialized and less intuitive for general-purpose data manipulation than Pandas.
Pandas vs NumPy’s core language and design philosophy cater to their strengths and use cases. Pandas extends Python’s capabilities for data manipulation, making it a natural choice for Python programmers working with structured data.
With its C-powered core and array programming focus, NumPy is optimized for numerical computations, forming the basis for complex data analysis and scientific computing in Python.
Understanding these core language aspects helps appreciate why each library excels in different scenarios and how they complement each other in the broader context of Python’s data science ecosystem.
Memory Usage
Memory usage is a crucial aspect in data science, mainly when working with large datasets. Pandas and NumPy differ in managing and utilizing memory, influencing their performance and suitability for various data tasks.
Pandas: Flexible but Memory-Intensive
Pandas is known for its flexibility in handling diverse data types, but this comes with a cost in terms of memory usage.
Dynamic Typing and Overhead:
- Each column in a Pandas DataFrame can have its data type, which allows for a mix of numerical, boolean, and object (string) types. While this is advantageous for data manipulation, it increases memory overhead.
- Pandas also store additional information like indices and data type information, contributing to higher memory usage.
Memory Consumption with Large Data:
- Pandas can be memory-intensive for large datasets, particularly those that don’t fit entirely into memory. This is due to its internal handling of data and the need to maintain various metadata.
Efficient with Certain Data Types:
- Pandas can be memory-efficient with specific data types, like categorical data. Memory usage can be significantly reduced by converting data to categorical types where appropriate.
NumPy: Memory-Efficient with Homogeneous Arrays
NumPy, in contrast, is designed for memory efficiency, especially when handling large arrays of numerical data.
Homogeneous Data:
- NumPy arrays are homogeneous, meaning all elements have the same data type. This uniformity allows NumPy to pack data more tightly in memory.
- The memory footprint of a NumPy array is typically smaller than a Pandas DataFrame with the same number of elements.
Lower Memory Overhead:
- NumPy arrays have a lower memory overhead than Pandas DataFrames. They lack the additional overhead of indexing and data type storage that Pandas has.
- This makes NumPy more suitable for tasks that involve large numerical datasets, where memory efficiency is key.
Pandas, with its flexible data handling capabilities, tend to consume more memory, which can be a limiting factor for very large datasets. NumPy, optimized for numerical computations with its homogeneous arrays, is more memory-efficient, making it a better choice for large-scale numerical computations.
Understanding these differences in memory usage helps data scientists and analysts choose the right tool based on the size of the dataset and the type of operations required, ensuring efficient use of resources in data processing and analysis.
Tools

Credits: Freepik
The Pandas vs NumPy tooling ecosystem enhances their functionality and ease of use. These tools range from extensions that augment their capabilities to integrated development environments (IDEs) that provide a more efficient workflow for data scientists and analysts.
Pandas: Rich Ecosystem for Data Analysis
Pandas benefits from a rich ecosystem of tools designed for data analysis, visualization, and integration with other data sources.
Data Visualization:
- Pandas integrates seamlessly with data visualization libraries like Matplotlib and Seaborn, allowing for the easy creation of plots and charts directly from DataFrames.
- This integration is invaluable for exploratory data analysis, where visualizing data trends and patterns is crucial.
IDEs and Notebooks:
- Jupyter Notebooks are a popular tool among data scientists using Pandas. They provide an interactive environment where data can be manipulated and visualized in a cohesive, narrative format.
- Other IDEs like PyCharm and Visual Studio Code also offer robust support for Pandas, including features like data frame viewers and interactive consoles.
Integration with SQL Databases:
- Pandas can directly interact with various SQL databases, enabling data to be read into DataFrames and vice versa. This feature is essential for data analysts working with relational databases.
NumPy: Tools for Scientific Computing
NumPy’s tooling ecosystem is geared towards numerical and scientific computing, reflecting its use in more technical and scientific applications.
Scientific Libraries:
- NumPy is the foundation for libraries like SciPy and scikit-learn, which extend its capabilities into scientific computing and machine learning.
- These integrations allow a seamless transition from data manipulation with NumPy to more complex scientific computations and machine learning model development.
Performance Optimization Tools:
- Tools like Numba and Cython can be used with NumPy to optimize performance, particularly for scenarios requiring heavy computational resources.
- These tools enable just-in-time compilation or C-level optimizations for Python code, significantly boosting the performance of NumPy operations.
Array Visualization:
- While not as focused on visualization as Pandas, NumPy can be used with visualization libraries to represent complex numerical data graphically.
In the debate of Pandas vs NumPy These complementing tools reflect their primary use cases. Pandas is supported by tools that enhance its data analysis and visualization capabilities, making it more accessible for data analysts and business professionals.
With its focus on scientific computing, NumPy is integrated with tools that enhance its computational efficiency and application in technical fields. This distinction in tooling ecosystems underscores Pandas and NumPy’s different roles in the data science landscape.
Open-Source Community
The open-source communities behind Pandas and NumPy play a pivotal role in their development, evolution, and widespread adoption. These communities contribute to the codebase and the documentation, tutorials, and overall ecosystem, making these libraries more accessible and powerful.
Pandas: A Vibrant and Diverse Community
Pandas boasts a vibrant and diverse open-source community, which has been instrumental in its growth and popularity.
Collaborative Development:
- The development of Pandas is highly collaborative, with contributions from data scientists, developers, and users from various industries. This diversity ensures that Pandas continues to evolve in ways that meet the practical needs of its user base.
Extensive Documentation and Resources:
- One of the strengths of Pandas is its extensive documentation, tutorials, and guides, many of which are contributed by the community. These resources are invaluable for new users and contribute to the library’s accessibility.
Active Forums and Support:
- Pandas has active forums and communities, including Stack Overflow, GitHub, and mailing lists, where users can seek help, share insights, and discuss features. This level of support is crucial for both beginners and experienced users.
NumPy: The Foundation of Python’s Scientific Ecosystem
NumPy’s community is foundational to Python’s scientific computing ecosystem, reflecting its status as a core library in numerical computing.
Core Library for Scientific Python:
- As a core library in the scientific Python ecosystem, NumPy attracts contributions from academics, researchers, and professionals in scientific computing.
- This contributes to its robustness and reliability, as users continuously test and improve it in demanding and diverse computational environments.
Global Contributions and Collaborations:
- NumPy benefits from global contributions, including those from major scientific and research institutions. These collaborations have helped shape NumPy’s efficiency and versatility for scientific computing.
Wide Range of Educational Resources:
- There are numerous tutorials, courses, and books dedicated to NumPy, especially focusing on its application in scientific and technical fields. This wealth of educational material helps foster a knowledgeable and skilled user community.
The open-source communities behind Pandas and NumPy are key to their success and widespread adoption. Pandas’ community ensures that it remains relevant and accessible for data analysis and manipulation, while NumPy’s community drives its growth as a fundamental tool for scientific and numerical computing.
The active participation and collaboration in these communities enhance the libraries and provide a rich learning environment for users at all levels.

Credits: Freepik
Operations
Pandas vs NumPy types of operations that are optimized for are reflective of their design philosophies and intended use cases. Understanding these operational strengths is crucial for leveraging each library effectively in data science projects.
Pandas: Rich in Data Manipulation Operations
Pandas is primarily designed for data manipulation and analysis, particularly with structured data. Its operations are diverse and robust, tailored to handle real-world data scenarios.
Data Cleaning and Preparation:
- Pandas excels in data cleaning and preparation tasks. It provides extensive functions for filtering data, filling missing values, and transforming data formats, essential steps in data preprocessing.
Complex Data Manipulation:
- The library supports complex operations like pivoting, reshaping, splitting, and merging datasets. These operations are invaluable for restructuring data and extracting meaningful insights.
Statistical Analysis:
- Pandas includes built-in functions for statistical analysis, making it easy to compute summaries, correlations, and other statistical measures on datasets.
Time Series Analysis:
- It offers specialized tools for time series data, such as date range creation and frequency conversion, which are critical in financial and economic data analysis.
NumPy: Specialized in Numerical Computations
NumPy is focused on numerical operations, particularly those involving large arrays. Its operations are optimized for performance and efficiency in mathematical computations.
Vectorized Mathematical Operations:
- NumPy uses vectorization, allowing operations to be applied to entire arrays without explicit loops. This is incredibly efficient for large-scale numerical computations.
Linear Algebra and Matrix Operations:
- The library provides comprehensive support for linear algebra operations, including matrix multiplication, decomposition, and eigenvalue calculations.
Statistical Functions:
- NumPy also includes essential statistical functions optimized for large numerical datasets, like mean, median, and variance.
Fourier Transforms and Shape Manipulation:
- Advanced operations like Fourier transforms and reshaping or resizing arrays are also part of NumPy’s core functionalities, catering to scientific and engineering applications.
The choice between Pandas and NumPy often comes down to the nature of the operations required. Pandas is the go-to library for complex data manipulation and analysis tasks, mainly when dealing with structured data and requiring data cleaning, reshaping, and summarization.
On the other hand, NumPy is ideal for tasks that demand efficient and high-performance numerical computations, such as linear algebra and large-scale mathematical operations.
Understanding these operational differences enables data scientists and analysts to choose the most appropriate tool for their data tasks, ensuring efficiency and effectiveness in their workflows.
Application
Pandas vs NumPy in regards to application extends across various domains, each leveraging the unique capabilities of these libraries. By examining their application in real-world scenarios, we gain insight into how they can be utilized effectively in different contexts.
Pandas: Versatile in Data Analysis and Manipulation,
Pandas is widely applied in domains that require extensive data analysis and manipulation of structured data.
Business Analytics:
- In the business world, Pandas is used for data analysis, financial modeling, and operational research. It helps in analyzing sales trends, customer behavior, and operational efficiencies.
Data Journalism:
- Data journalists use Pandas for data wrangling and analysis to uncover stories hidden in data. Its ability to handle diverse data sources and perform complex data manipulations is key.
Academic Research:
- Researchers in fields like social sciences and humanities use Pandas for data cleaning, exploration, and visualization, making deriving insights from complex datasets easier.
NumPy: Fundamental in Scientific and Technical Computing
NumPy’s application is rooted in scientific and technical computing, where numerical and array-based operations are predominant.
Scientific Computing:
- NumPy is used in various scientific research domains, such as physics, chemistry, and astronomy, for numerical simulations, data analysis, and algorithm development.
Engineering Applications:
- In engineering, especially in signal processing, image processing, and computational mechanics, NumPy is essential for handling complex calculations and simulations.
Machine Learning and Artificial Intelligence:
- NumPy forms the basis for many machine learning algorithms, especially in preprocessing steps, feature extraction, and mathematical operations.
Pandas vs NumPy, though often used together, find their strengths in different applications. Pandas is a staple in scenarios requiring robust data manipulation and analysis capabilities, especially with structured data.
NumPy’s efficiency in numerical operations is indispensable in scientific, engineering, and machine learning applications. Understanding where each library excels helps select the right tool for specific applications, ensuring optimal outcomes in various data-driven projects.
Discover the distinct worlds of Pandas vs NumPy in this concise comparison table. Delve into their unique strengths, applications, and characteristics, all distilled into an easy-to-digest format.
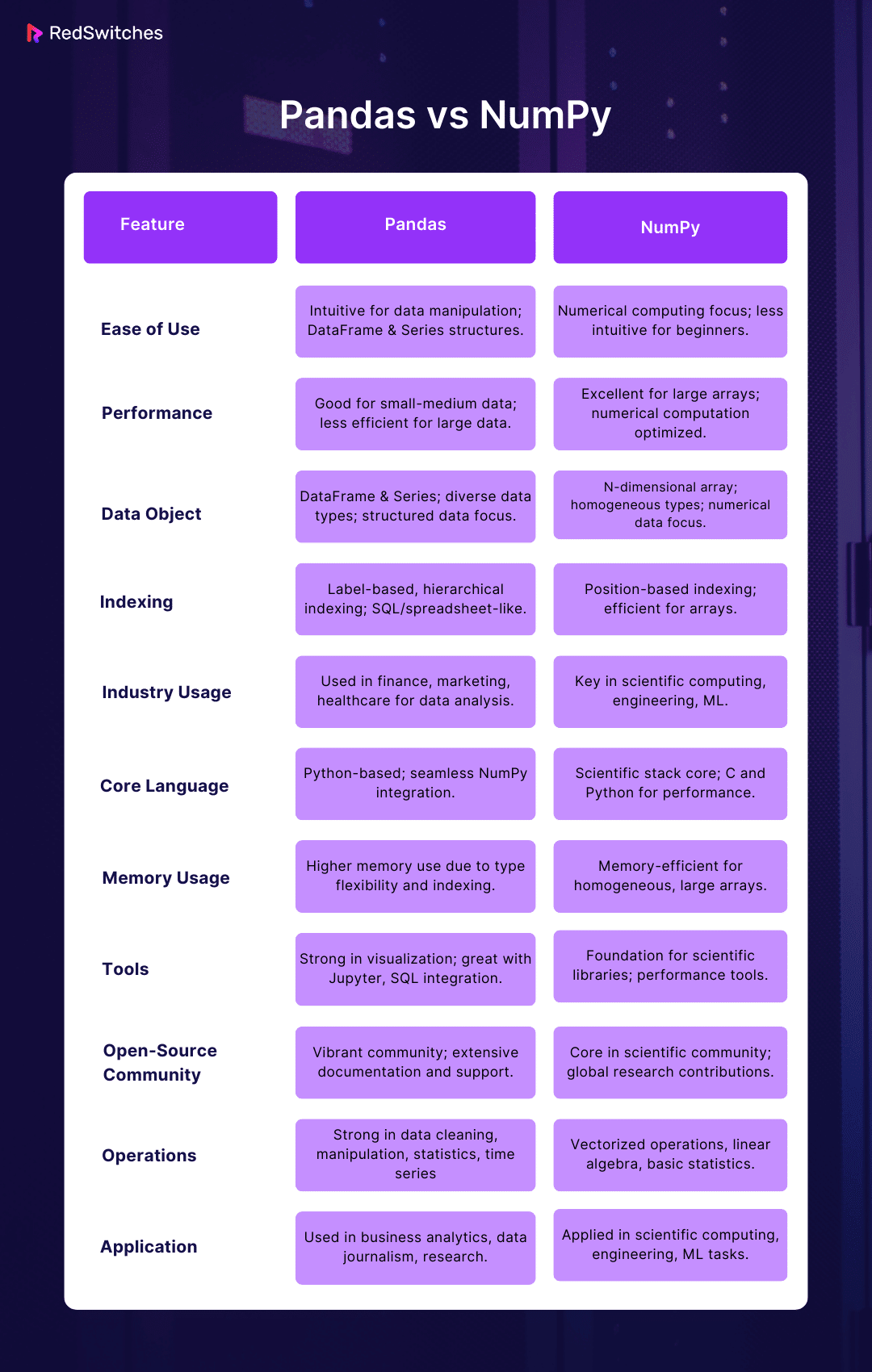
Also Read Cloud Computing vs. Virtualization
Pandas Examples: Simplified for Easy Understanding

Pandas, a versatile tool in Python, simplifies data manipulation and analysis. Here are a few practical examples showcasing its capabilities:
1. Reading Data
Pandas makes it easy to load data from various sources. For instance, reading a CSV file:
import pandas as pd
data = pd.read_csv(‘file.csv’)
2. Data Inspection
Quickly inspect your data to understand its structure and content:
# View the first few rows
data.head()
# Summary statistics
data.describe()
3. Handling Missing Values
Identify and fill missing values in your dataset:
# Check for missing values
data.isnull().sum()
# Fill missing values
data.fillna(method=’ffill’, inplace=True)
4. Filtering Data
Easily filter and select data based on conditions:
# Filter rows where column ‘A’ is greater than 50
filtered_data = data[data[‘A’] > 50]
5. Grouping and Aggregation
Group data and perform aggregate functions:
# Group by ‘Category’ and calculate mean of ‘Values’
grouped_data = data.groupby(‘Category’)[‘Values’].mean()
6. Creating New Columns
Add new columns based on existing data:
# Create a new column ‘C’ as the sum of ‘A’ and ‘B’
data[‘C’] = data[‘A’] + data[‘B’]
7. Data Visualization
Pandas integrates with plotting libraries for quick visualizations:
# Plotting data
data.plot(kind=’bar’, x=’Category’, y=’Values’)
These examples demonstrate how Pandas can be employed for a range of data tasks, making it a powerful ally in data analysis and manipulation.
NumPy Examples: Practical and User-Friendly

NumPy is a cornerstone for numerical computing in Python. Here are some straightforward examples to illustrate its practical use:
1. Creating Arrays
NumPy excels in creating and manipulating arrays:
import numpy as np
# Creating a simple array
arr = np.array([1, 2, 3, 4, 5])
2. Array Operations
Performing arithmetic operations with arrays is straightforward:
# Adding a constant to an array
new_arr = arr + 10
3. Multi-dimensional Arrays
Creating and working with multi-dimensional arrays is a key feature:
# Creating a 2D array (matrix)
matrix = np.array([[1, 2], [3, 4]])
4. Statistical Calculations
Quickly compute statistical measures:
# Calculating the mean
mean = np.mean(arr)
# Calculating the standard deviation
std_dev = np.std(arr)
5. Linear Algebra
NumPy supports various linear algebra operations:
# Matrix multiplication
result = np.dot(matrix, arr)
6. Reshaping Arrays
Change the shape of arrays to fit your needs:
# Reshape a 1D array into a 2D array
reshaped = arr.reshape((5, 1))
7. Boolean Indexing
Filtering elements based on conditions:
# Filtering values greater than 2
filtered = arr[arr > 2]
These examples showcase how NumPy’s array-centric approach simplifies complex numerical computations, making it a valuable tool for a wide range of applications.

Credits: Freepik
Conclusion
As we’ve navigated through the intricacies of the debate Pandas vs NumPy, it’s clear that both libraries offer distinct advantages crucial in the data science realm. Whether you’re dealing with structured data manipulation using Pandas or diving into the depths of numerical computing with NumPy, these tools are indispensable for anyone looking to harness the power of data.
But remember, the journey doesn’t end with understanding these tools. The real magic happens when you apply this knowledge to real-world scenarios, and that’s where RedSwitches comes into play.
Embarking on your data journey with RedSwitches means not just dreaming about data success but actively achieving it. Visit RedSwitches today and see how their solutions can transform your approach to data projects with their dedicated server.
With the right tools and partner, the possibilities in data science are endless. Let RedSwitches be your partner in this journey, and together, let’s unlock the full potential of data.
FAQs
Q. Which is Better: Pandas or NumPy?
The choice between Pandas vs NumPy depends on the task. Pandas is better for data manipulation and analysis with structured data, while NumPy excels in numerical and mathematical computations, particularly with large arrays.
Q. Should I Learn NumPy or Pandas First?
Learning NumPy first is advisable as it provides a foundational understanding of array-based computing, which is beneficial when working with Pandas. Pandas build on NumPy, making it easier to grasp after understanding NumPy.
Q. What is the Difference Between NumPy Mean and Pandas Mean?
NumPy mean and Pandas mean both calculate the average of given numbers. The key difference lies in their data handling: NumPy mean is faster and more suitable for arrays of numerical data, while Pandas mean can handle missing data and offers more flexibility with DataFrame and Series objects.
Q. What is the Difference Between NumPy Type and Pandas Type?
NumPy types are essentially Python data types but with a focus on fixed-size, numerical data types (like np.int32, np.float64). Pandas types are more diverse, aligning with Python and NumPy types but also more flexible types like object for text and mixed data, and specialized types like Categorical.
Q. What is the main difference between Pandas and NumPy?
NumPy is designed for numerical computations, whereas Pandas is designed for data manipulation and analysis.
Q. How are Pandas and NumPy related to Python?
Both Pandas and NumPy are open-source Python libraries commonly used in data science and data manipulation.
Q. Can you explain the key differences between Pandas and NumPy?
While NumPy focuses on numerical operations using arrays, Pandas provides high-performance data structures and data analysis tools.
Q. Is it better to use NumPy or Pandas for data manipulation?
Pandas is better suited for data manipulation and analysis compared to NumPy, as it offers more powerful and intuitive tools for such tasks.
Q. How can I install Pandas on my system?
You can install Pandas by using the command ‘pip install pandas’ in your Python environment.
Q. In terms of performance, is Pandas better than NumPy?
Yes, for data manipulation and analysis tasks, the performance of Pandas is generally better than that of NumPy.
Q. What type of operations can be performed using Pandas?
Pandas can handle various operations including data cleaning, merging, reshaping, and analysis, making it a versatile tool for data manipulation.
Q. Are Pandas and NumPy both Python libraries?
Yes, both Pandas and NumPy are Python libraries commonly used for data manipulation and scientific computing with Python.
Q. How do NumPy and Pandas compare to each other?
NumPy is “the fundamental package for scientific computing with Python”, while Pandas is built on top of the NumPy package, offering tools for data manipulation and analysis.
Q. What are the main features of Pandas and NumPy?
NumPy provides support for large, multi-dimensional arrays and matrices, while Pandas offers data structures like DataFrame and Series for efficient data manipulation and analysis.
