
If you’re a command line fan, you know the frustration of scrolling and reading through a lot of text to find what you’re looking for. For instance, finding relevant information in a long log file can take several minutes. The problem worsens when trying to find content that matches a specific pattern. You can easily overlook a match and might have to start all over again.
In Linux, you can use powerful command-line tools for simplifying and speeding up tasks such as finding specific text patterns within files.
grep, which stands for “global regular expression print” is a popular tool that uses regular expressions and is often considered versatile for searching and matching text pattern files.
This blog post will explore using grep and regular expressions to find text patterns within files. Whether you are a system administrator, developer, or Linux enthusiast, understanding these techniques will empower you to perform efficient searches, quickly extract valuable information, and automate a long list of mundane tasks.
We will discuss the basics and give practical examples to demonstrate using grep regex to perform search and pattern-matching operations.
Table of content
Understanding grep and Regular Expressions
grep, available on Linux, Unix, and similar operating systems, is a powerful utility to search for strings or patterns of text. It derives most of its power from regular expressions (a string of special characters that define a pattern). Grep uses these patterns to search target strings or patterns in text files or streams.

The grep command-line utility is one of the oldest and most popular Unix commands and uses regular expressions as its primary tool for searching for specific strings of characters.
Regular expressions, or regex, are powerful tools for matching text patterns in programming languages and applications. They are used to quickly search through large volumes of data or validate user input.
Regular expressions are built from a set of special characters that have meaning within grep searches. These include:
^– used at the start of an expression to indicate it should only match at the beginning of a line$– used at the end of an expression to indicate it should only match at the end[]– used to group individual character classes|– used as an OR operator()– used to group multiple related expressions together\– used as an escape character before other special characters*– used as a wildcard for zero or more occurrence(s)
Prerequisites to Using grep Regex Utility:
You only need access to the command line of a Linux box to use grep. We highly recommend sample text files, such as old log files, to try out the options described below:
Before we dive into using grep, let’s discuss regex and understand the types of regex commonly used with the grep utility.
The Three Types of Regex
Regular expressions in grep are grouped into many categories based on the patterns and characteristics they provide. Here are some commonly used types of regular expressions in grep:
Basic Regular Expression (BRE)
BREs are used for basic pattern-matching operations. They support major metacharacters, including:
Symbol Descriptions
. replaces any character
^ matches the start of the string
$ matches the end of the string
* matches zero or more times the preceding character
\ Represent special characters
() Groups regular expressions
? Matches up exactly one character
[] Matches any character within the brackets
Extended Regular Expressions (ERE)
EREs extend the capabilities of BREs with additional features and metacharacters. For instance, they include metacharacters like + (matches one or more occurrences), ? (matches zero or one occurrence), and (grouping). To use extended regular expressions in grep, use -E or –extended-regexp flag with the command.
Perl Compatible Regular Expressions (PCRE)
PCRE provides advanced regular expression features and syntax similar to Perl regular expressions. They offer additional metacharacters, such as \b (word boundary), \d (digit), \s (whitespace), and \w (word character). Use the -P or –perl-regexp flag to use PCRE in grep commands.
By default, grep utilizes the BRE syntax. If you wish to use ERE or PCRE formats, use the appropriate flag with the command.
How to Use grep regex to Find Patterns and Matches
Now that you have a theoretical understanding of grep and the role of regular expressions, let’s see some practical usage of the utility.
We’ll start with a look at the basic grep regex usage.
Basic Syntax for grep regex
The syntax for the grep command includes regular expressions in the following format:
# grep [regex] [filename]
Note that grep works with the standard output if you don’t specify a filename.
Here’s the grep syntax in action:
We need to search for the word ‘and’ in the test file named ‘redswitches_regex.txt.’ For this, we’ll use the following command:
# grep and redswitches_regex.txt
In the following screenshot, you can see that the grep utility printed all the lines containing the target string (and) and highlighted all occurrences.

Regex adds a lot of power to how grep searches and matches patterns and strings.
We’ll now go through some examples of using grep to find complex matches and patterns using regular expressions.
Literal Matches
Literal matches perform an exact match for the character string given. The above example of a search for the string ‘and’ shows a literal match. You may also add case-sensitive patterns for variation of the search string. For instance, you can use the following variation to search for the string “And”.
# grep And filename
Here’s another example:
You can find all the lines containing an all-lowercase and a case-sensitive variation of a string with the following command:
# grep “Regular Expression” redswitches_regex.txt
# grep “Regular expression” redswitches_regex.txt
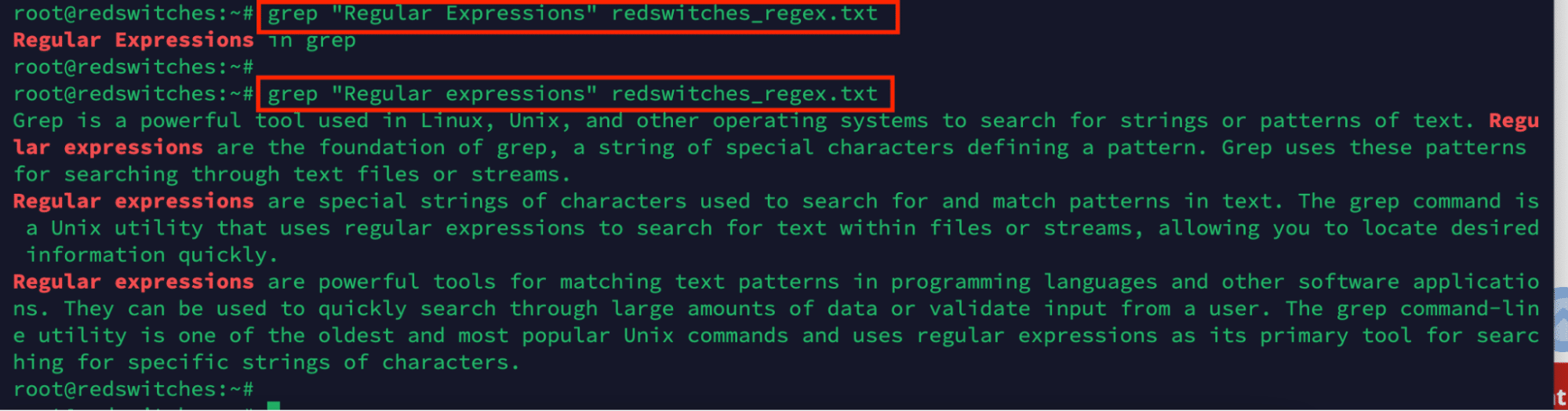
As you can see, the command found all the occurrences of both variations in the file.
Anchor Matches
Anchor matches are regex patterns that match a string’s start or end. They are helpful when searching for patterns at the beginning or end of lines or between two words.
There are two main anchor matches:
^(caret) – Matches the beginning of a line$(dollar sign) – Matches the end of a line
For example, to search for a sentence beginning with “Test” in a file, you can use the following grep regex combination:
# grep ^Test redswitches_regex.txt

Similarly, to find lines ending with the word “auto” in the redswitches_regex.txt file, run:
# grep auto$ redswitches_regex.txt

Note that the caret ^ symbol is placed at the start of the target string, while the dollar $ symbol is placed at the end of the target string.
Match A Character
You can use the dot . symbol to match any character in a regex pattern. This is an incredibly useful regex because you can use it to find patterns contained between two characters. You can use this symbol to match any character, including a letter, number, symbol, or space.
For instance, consider the following grep regex example:
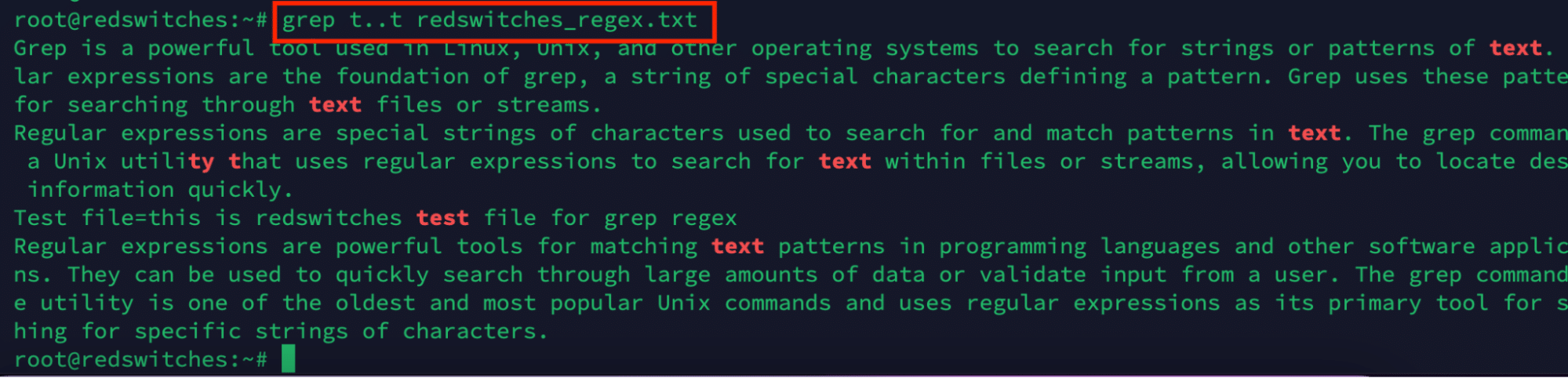
#grep t..t redswitches_regex.txt
As you can see, the command outputs all instances of four-letter words starting and ending with t (text, ty t, and test)
Consider another example command:
# grep ..x$ redswitches_regex.txt
The command finds all lines containing three-letter words ending with an ‘x’ (gex,nux, and nix).

Bracket Expressions
In grep regex, bracket expressions (character classes) match a single character from a specific set of characters. They allow you to define a set of characters and match any from that set.
Here are some key points about bracket expressions in grep regex:
- Syntax: Bracket expressions are enclosed within square brackets
[]. For example, [abc] matches any character: ‘a’, ‘b’, or ‘c.’ - Character Range: You can specify a range of characters using a hyphen
-inside the bracket expression. For example, [a-z] matches any lowercase letter from ‘a’ to ‘z.’ - Negation: You can negate a bracket expression by placing a caret
^as the first character inside the brackets. For example, [^0-9] matches any character without a digit. - Combining Characters: You can combine multiple characters and ranges inside a bracket expression. For example, [a-zA-Z0-9] matches any alphanumeric character, including upper and lower cases.
- Special Characters: Some characters have special meanings within bracket expressions. To match these special characters literally, you can escape them with a backslash
\. For example, [\$] matches a dollar sign character. - Metacharacters Inside Bracket Expressions: Some metacharacters lose their special meaning and are treated as ordinary characters inside a bracket expression. These include the caret
^, hyphen-, and right square bracket].
Bracket expressions provide a flexible and concise way to match specific sets of characters in grep regular expressions. They are useful for pattern matching and filtering text containing specific special characters.
Let’s see the bracket expression in action.
Use the following statement to match everything except “and” or “end”:
# grep [ae]and redswitches_regex.txt
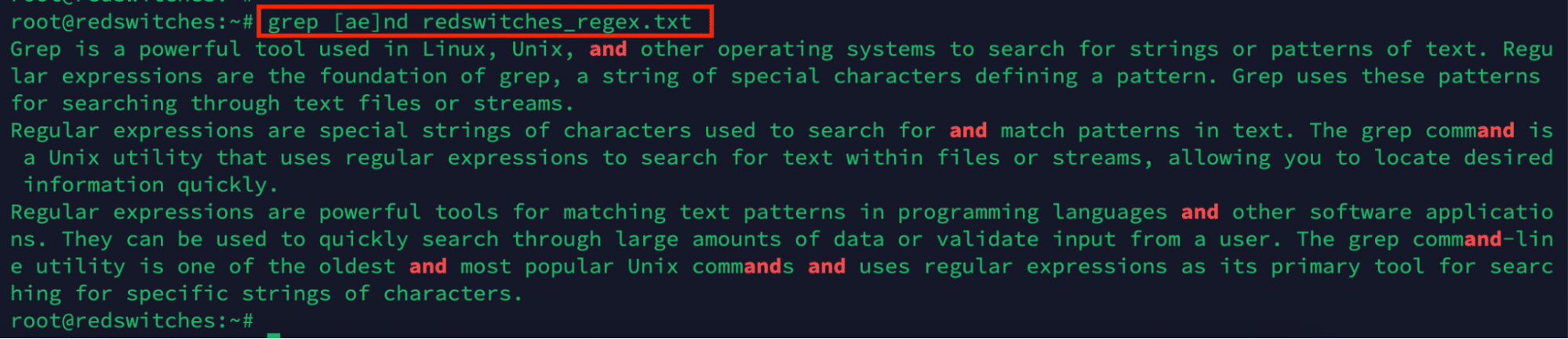
Use bracket expressions with a hyphen (-) between the first and last letter to provide a character range. For instance, use the following statement to look for all instances of uppercase letters:
# grep [A-Z] redswitches_regex.txt
![grep[A-Z]](https://www.redswitches.com/wp-content/uploads/2023/08/grepA-Z.png)
Repeat Pattern Zero or More Times
The * metacharacter in grep regex can be used to repeat a pattern zero or more times.
Here’s an example for demonstration:
# grep 'pa*ttern' redswitches_regex.txt
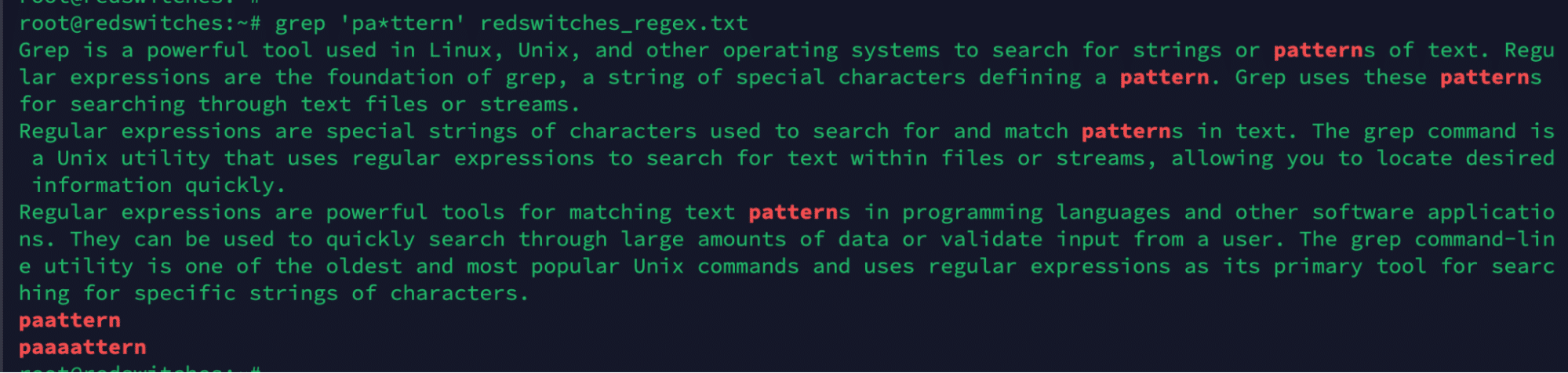
In this example, pa*ttern is the regex pattern you want to match. The * metacharacter after the character a allows for zero or more occurrences of the preceding character (a). So, this command will match strings like “pttern”, “patern”, “paatern”, and “pattern” in the file.
Escaping Metacharacters
In grep regex, you can escape metacharacters to treat them as literal characters instead of their special meaning. Here’s how you can escape metacharacters in grep regex:
- Backslash (
\): Use a backslash before a metacharacter to escape it. For example, to match the dot metacharacter (.), you would use\. in the regex pattern. - Square Brackets (
[]): If you want to match a literal square bracket, you can escape it with a backslash. For example, to match a literal opening square bracket ([), you would use\[in the regex pattern. - Parentheses (
()): Like square brackets, you can escape parentheses with a backslash to match them literally. For example, to match a literal opening parenthesis(, you would use\(in your regex pattern. - Asterisk (
*): The asterisk is a metacharacter representing zero or more occurrences of the preceding element. To match a literal asterisk, escape it with a backslash (\*). - Plus Sign (
+): Similar to the asterisk, the plus sign is a metacharacter that represents one or more occurrences of the preceding element. To match a literal plus sign, escape it with a backslash (\+). - Question Mark (
?): The question mark is a metacharacter representing zero or one occurrence of the preceding element. To match a literal question mark, escape it with a backslash (\?). - Curly Braces (
{}): Curly braces are used for quantifiers to specify the number of occurrences. To match literal curly braces, escape them with a backslash (\{or\}).
By escaping these metacharacters, you can ensure they are treated as literal characters in your grep regex pattern.
Quantifiers
Quantifiers are special symbols that match a certain number of occurrences in a regex pattern. There are four main quantifiers:
*(asterisk) – Matches zero or more occurrences of the preceding character or expression.+(plus sign) – Matches one or more occurrences of the preceding character or expression.-
?(question mark) – Matches zero or one occurrence of the preceding character or expression. {}(curly brackets) – Matches exactly n occurrences of the preceding character or expression.
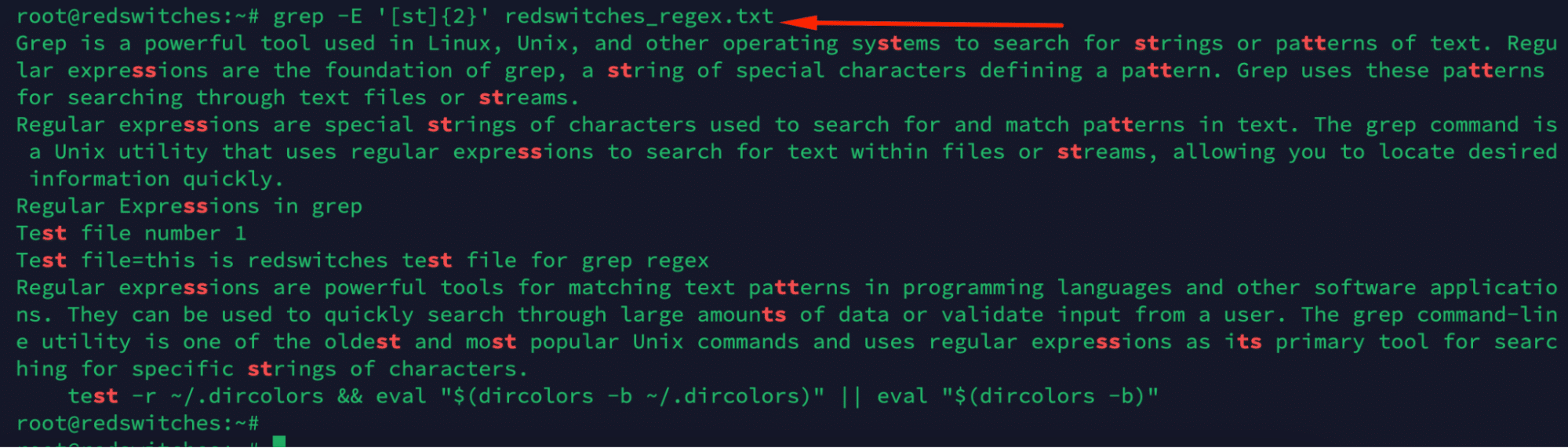
For example, use the following command to search for strings with two letters, ‘st’. The output will contain all occurrences of the combinations ss, tt, and st
# grep -E '[st]{2}' redswitches_regex.txt
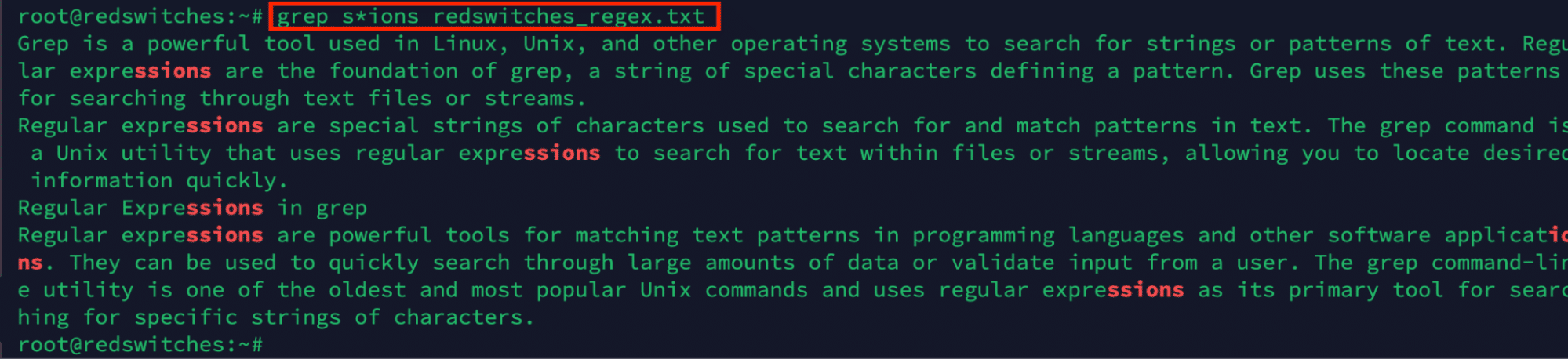
The * symbol occurs zero or more times in a pattern. Run the following command to see how it works:
# grep s*ions redswitches_regex.txt
Alternations
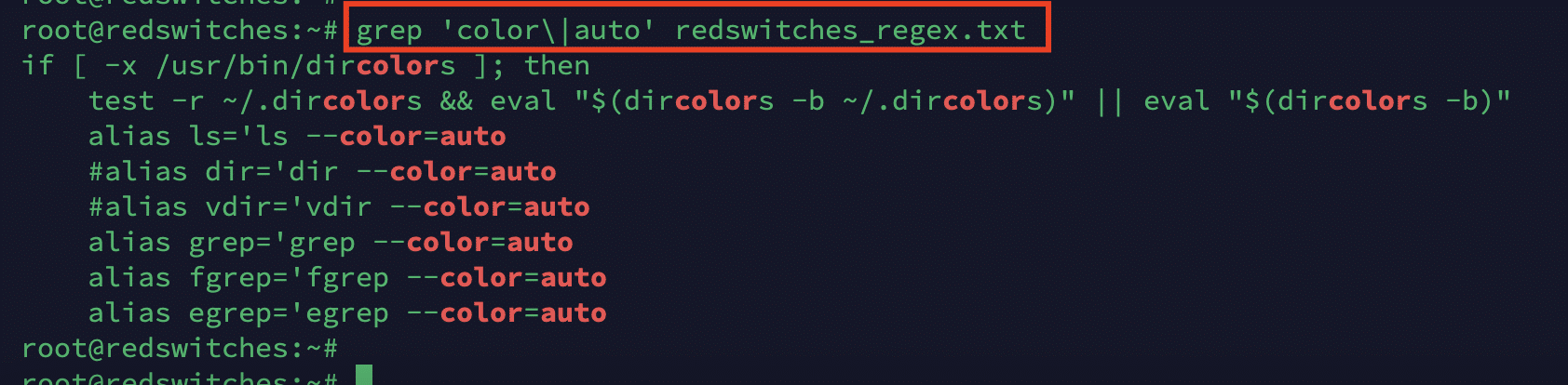
Alternation allows you to provide alternative matches. When creating the regex for these commands, separate the alternative strings using single quotes and an escaped pipe character (\|). Here’s a sample statement that searches for the words “color” or “auto” in the .bashrc file
# grep 'color\|auto' redswitches_regex.txt
Backslash Expression
Several grep metacharacters have a backslash and a regular character. Some of the most popular special backslash expressions are:
\b: Match a word boundary.
\>: Match an empty string at the end of a word.
\<: Match an empty string at the beginning of a word.
\s: Match a space.
\w: Match a word.
Here’s a simple example of using particular backslash expressions to search for a line containing the unique character ‘/’.
# grep '\/' redswitches_regex.txt

Grouping
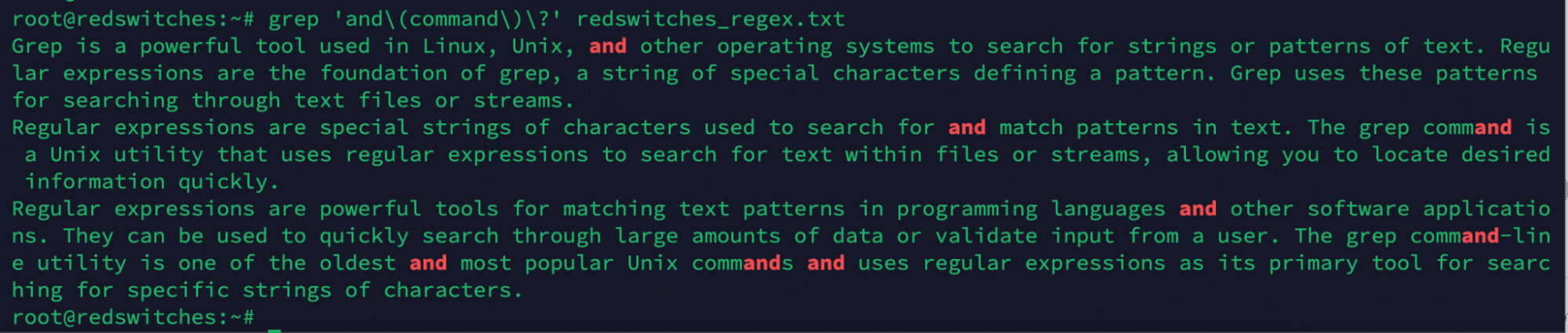
Grouping is a regex technique used to apply quantifiers, alternations, and other operations to multiple characters or expressions. To group characters or expressions, use parentheses ( ).
# grep 'and\(command\)\?' redswitches_regex.txt
In the above command, we searched for the string “and” and made the string “command” optional. Since the command is an option, the output is highlighted and occurs in commands.
Conclusion
grep is a powerful command-line tool that utilizes regular expressions (regex) to search and match text file patterns. Regex patterns in grep allow precise searching by defining specific character sequences or patterns. We showed how grep regex is a flexible way to search for patterns in text files, making it an essential tool for many Linux and Unix users.
If you’re reading about grep regex, you probably use a Linux distro to power your projects. Here at RedSwitches, we offer exceptional bare metal hosting services and give our users the confidence that their projects and business operations are always up and running!
We invite you to a free chat with our support engineers to learn more about our services and how we can help you build and maintain a dependable bare-metal dedicated server infrastructure.
Frequently Asked Questions (FAQs)
Q-1) Can grep use advanced regex features?
Yes, grep supports advanced regex features like capturing groups, backreferences, lookaheads, and lookbehinds. These features may change depending on how your distro implements the grep utility.
Q-2) Can I search across multiple files with grep?
You can tell grep to look for a pattern in multiple files by giving it a list of multiple file names as arguments. For instance, you can use grep pattern file1.txt file2.txt to search through two files.
Q-3) How can I use grep to perform a case-insensitive search?
You can use the -i option to execute a case-insensitive search. Use the syntax: grep -i pattern, as in: file.txt.
