
awk is a versatile, powerful utility in almost all Unix-like operating systems. This feature-rich utility is used in command-line and scripts for advanced text processing and data extraction.
Users prefer awk as the go-to utility for handling structured text data, making it a valuable tool for parsing and manipulating information within files.
In this tutorial, we’ll discuss the fundamentals of using awk command in linux for text extraction and processing. We’ll start with a short introduction to awk. Next, we’ll discuss critical aspects of awk syntax, such as variables, patterns, and actions.
Table of Contents
- What is awk?
- The Basic Syntax of awk in Linux & Unix
- How to Use the awk Command
- The AWK Variables
- The awk Patterns
- The awk Actions
- Conclusion
- FAQs
What is awk?
The name awk is an acronym consisting of the names of the original developers—Alfred Aho, Peter Weinberger, and Brian Kernighan.
Thanks to its concise and expressive syntax, awk excels at defining patterns, specifying actions, and applying these rules to process input lines. It operates on a line-by-line basis, making it well-suited for tasks such as filtering and reformatting data, extracting specific fields, and performing calculations.
awk is widely used in various scenarios, from simple one-liners for quick text processing tasks to more complex scripts for advanced data manipulation. Its flexibility and ease of use make it an essential tool for system administrators and anyone working with textual data in a Linux environment.
Let’s now take a look at the basic syntax of the awk utility.
Also Read: 13 Examples That Showcase the xargs Command in Linux
The Basic Syntax of awk in Linux & Unix
Regardless of the OS, the basic awk syntax is:
# awk [options] 'program' input-file(s)
Where:
- options: awk options are command-line options to modify the utility’s behavior.
- The program: contains rules and actions enclosed in single quotes (‘). A program has the general form: pattern { action }. The pattern specifies when the action is to be executed. The action is executed for every input line if the pattern is omitted.
- input-file(s): These are the file(s) that awk processes. If no files are specified, awk reads from the standard input (usually the keyboard, a pipe, or a redirection).
Common AWK Options
| Option | Description |
| -f [filename] | Used to designate the location of the awk script’s file. Reads the awk program source from the given file rather than the first parameter passed in at the command line. |
| -v | Allocates a variable. |
| -F [separator] | Indicates the separator for files. A space is used as the separator by default. |
How to Use the awk Command
Users can execute diverse operations on an input file or text with the awk utility. Common operations include:
- Go line by line through a file.
- Divide the file or line of input into fields.
- Examine the input line or fields against the designated pattern or patterns.
- Apply different operations to the corresponding lines mentioned in the awk command syntax.
- Arrange the lines of output in specific formats.
- Execute string and arithmetic operations.
- Use output loops and basic control flow statements for fine control over the utility operations.
- Transform the data and files using the given structure.
- Produce reports in the user-specified formatted format.
Also Read: 6 Simple Examples of Using the Linux watch Command
How Does a Typical awk Command Work?
Here’s a general explanation of how a typical awk command works:
Step #1: Reading Input
awk reads the input line by line from either a specified file or the standard input (if no file is specified).
Each line is treated as a record, and a field separator separates fields within the record (the default field separator is the whitespace character).
Step #2: Pattern Matching
For each line, awk evaluates the specified patterns.
Patterns can be regular expressions or logical conditions that define when a particular action should be taken.
Step #3: Action Execution
When a line matches a pattern, the associated action block is executed.
In an awk command, actions are enclosed in curly braces { } and consist of one or more statements.
The awk actions are flexible and can include built-in functions, arithmetic operators, and print action statements. If you don’t specify a pattern, awk applies the specified actions to every line of input fields, effectively acting as a filter or processor for the entire file.
Step #4: Output
awk can generate standard output based on the specified actions. The print statement is commonly used to display or format output.
The utility can process multiple input files sequentially, allowing users to concatenate or process data from different sources.
Here’s a simple example to illustrate how awk works.
Suppose you have a file named data.txt with the following content:
Alice 25 Bob 30 Charlie 22
The following awk command calculates the average age and prints it:
# awk '{ sum += $2 } END { print "Average Age:", sum/NR }' data.txt
In this example:
- sum += $2 accumulates the sum of the second field (ages).
- END { print “Average Age:”, sum/NR } calculates and prints the average age after processing all lines.
Also Read: A Guide on How to Install and Use Linux Screen Command in 2024
The AWK Variables
awk uses predefined variables like $0 (entire line), $1, $2, … (individual fields) and provides extensive functions for string operations like manipulation, numeric calculations, and more.
Users can define custom variables within awk scripts.
These built-in variables can carry information about the input data, processing state, and other aspects. Here are some commonly used awk native variables with examples:
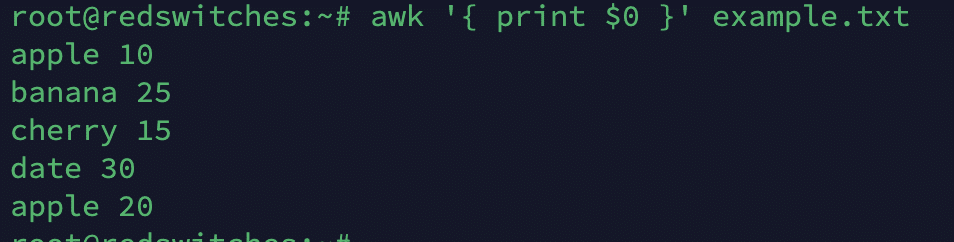
$0
This variable represents the entire input record (the entire line). A typical example is:
# awk '{ print $0 }' example.txt
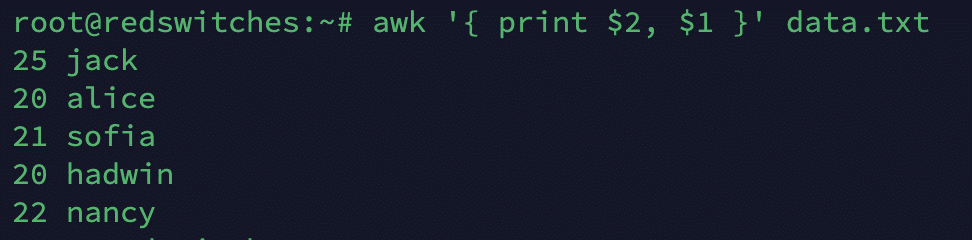
$1, $2, …
This variable represents individual fields within a record, where $1 is the first field, $2 is the second field, and so on. A typical example is:
# awk '{ print $2, $1 }' data.txt
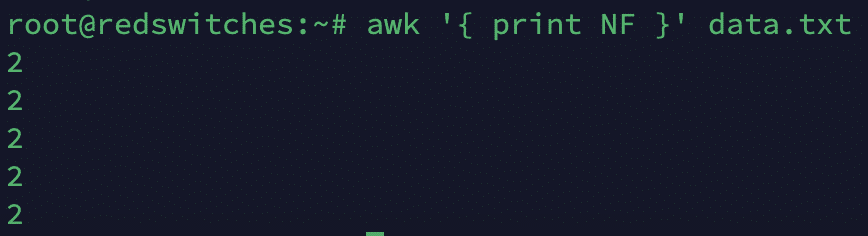
NF
This Number of Fields variable gives the total number of fields in the current record.
# awk '{ print NF }' data.txt
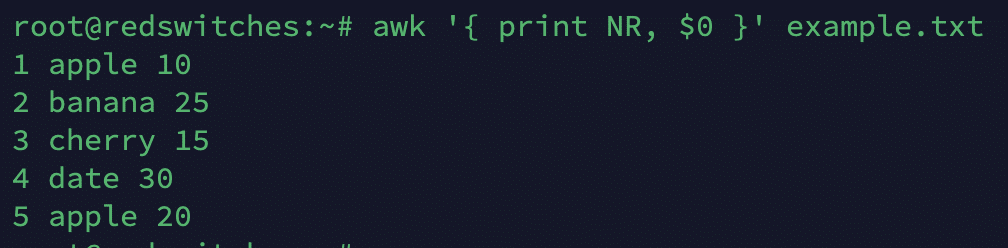
NR
This variable gives the current record (line) number.
# awk '{ print NR, $0 }' example.txt
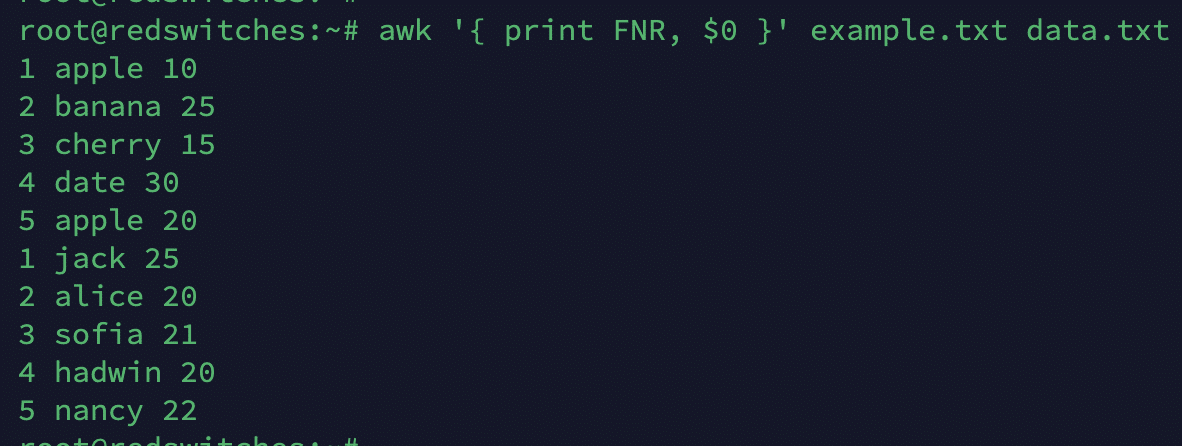
FNR
This variable is similar to NR but resets for each input file. As such, it represents the record number within the current file.
# awk '{ print FNR, $0 }' example.txt data.txt
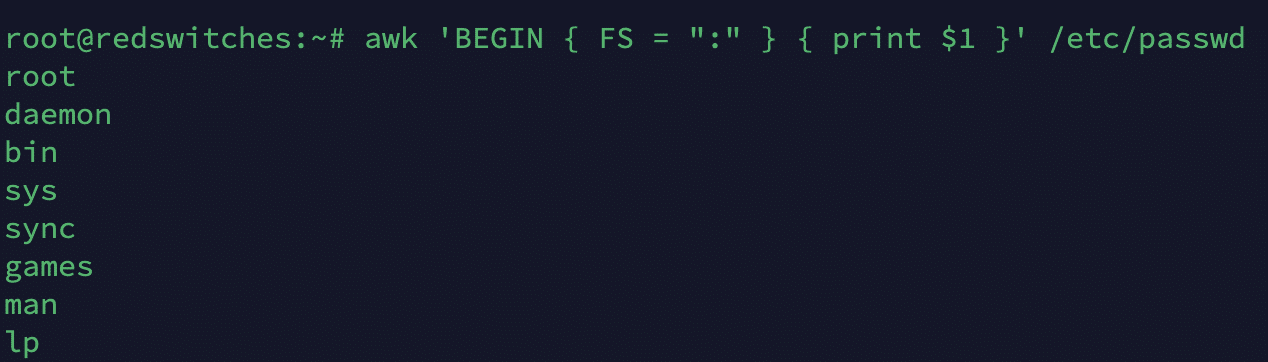
FS
FS stands for the Field Separator, and this field variable defines the character or regular expression used to separate fields.
# awk 'BEGIN { FS = ":" } { print $1 }' /etc/passwd
OFS
Standing for the Output Field Separator, this variable determines the separator for the print statement.
# awk 'BEGIN { OFS = "\t" } { print $1, $2 }' data.txt

RS
The RS variable stands for the Record Separator and defines the character or regular expression used to separate records.
# awk 'BEGIN { RS = "\n\n" } { print $0 }' data.txt

ORS
Standing for the Output Record Separator, ORS determines the separator for the print statement.
# awk 'BEGIN { ORS = "\n\n" } { print $1, $2 }' data.txt

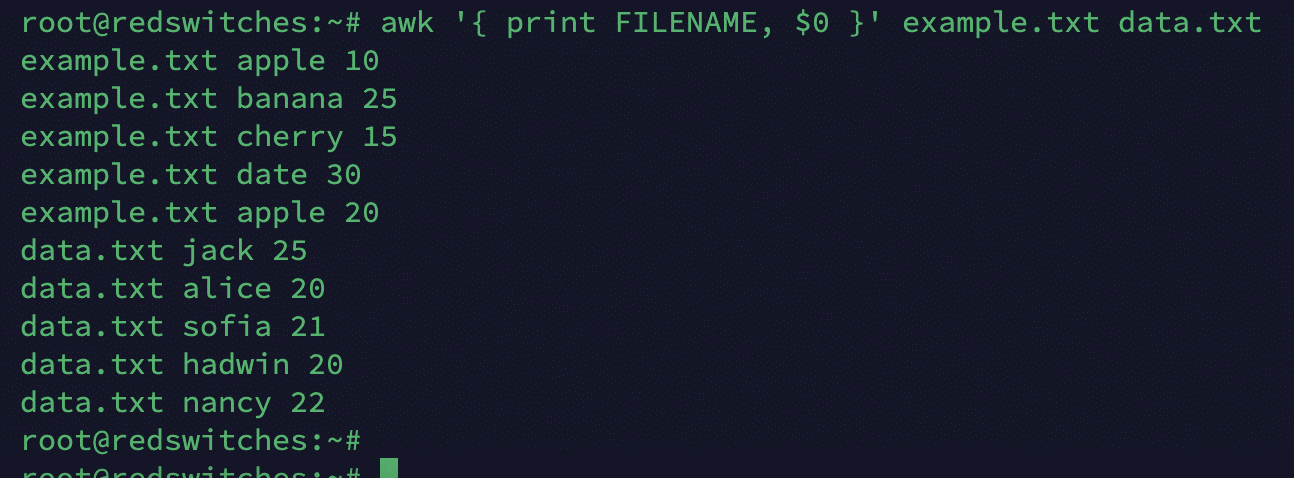
FILENAME
This variable contains the name of the current input file being processed by an awk command.
# awk '{ print FILENAME, $0 }' example.txt
The awk Patterns
The awk patterns are expressions or conditions that awk uses to determine which records (usually lines of input) it should process.
When an awk script runs, it reads its input one record at a time, and for each record, it checks against the specified patterns. The corresponding action (enclosed in braces) is executed if a record matches a pattern.
Patterns in awk can range from simple string matching to complex regular expressions. You can even include compound conditions in awk patterns.
Types of awk Patterns
You can use the following awk patterns in the terminal and scripts:
Regular Expression Patterns
- /^b/: This regular expression matches lines where the content begins (^) with the letter b.
- { print }: The action block is used to print the entire line for the matched pattern.
- Enclosed between slashes (/regex/): This block is used to match lines based on regular expression rules.
The syntax is:
/pattern/ { action }
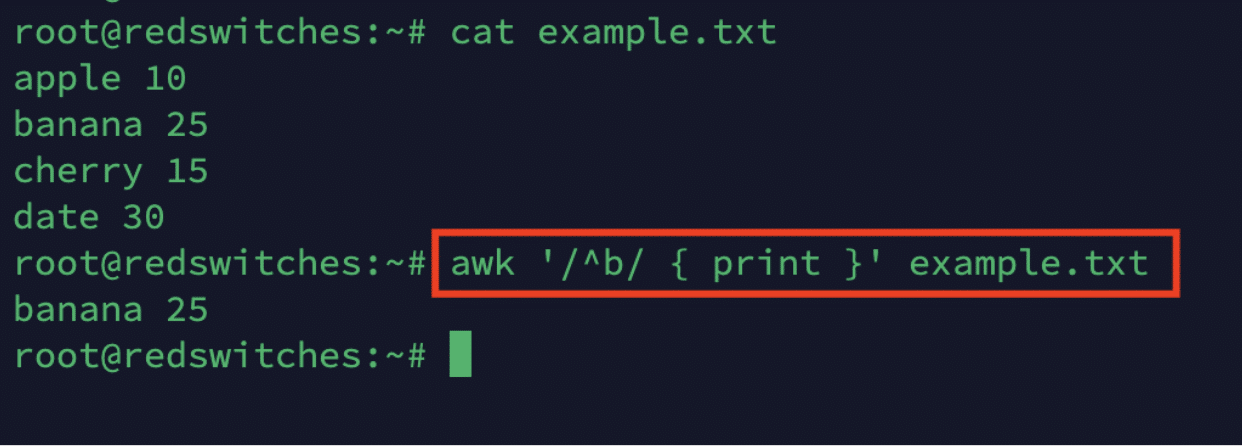
Let’s say you have a file named example.txt with the following content:
apple 10
banana 25
cherry 15
date 30
You can use the following awk command to select and print lines where the fruit name starts with the letter b.
# awk '/^b/ { print }' example.txt
Comparison and Relational Expression Patterns
Numeric Comparison
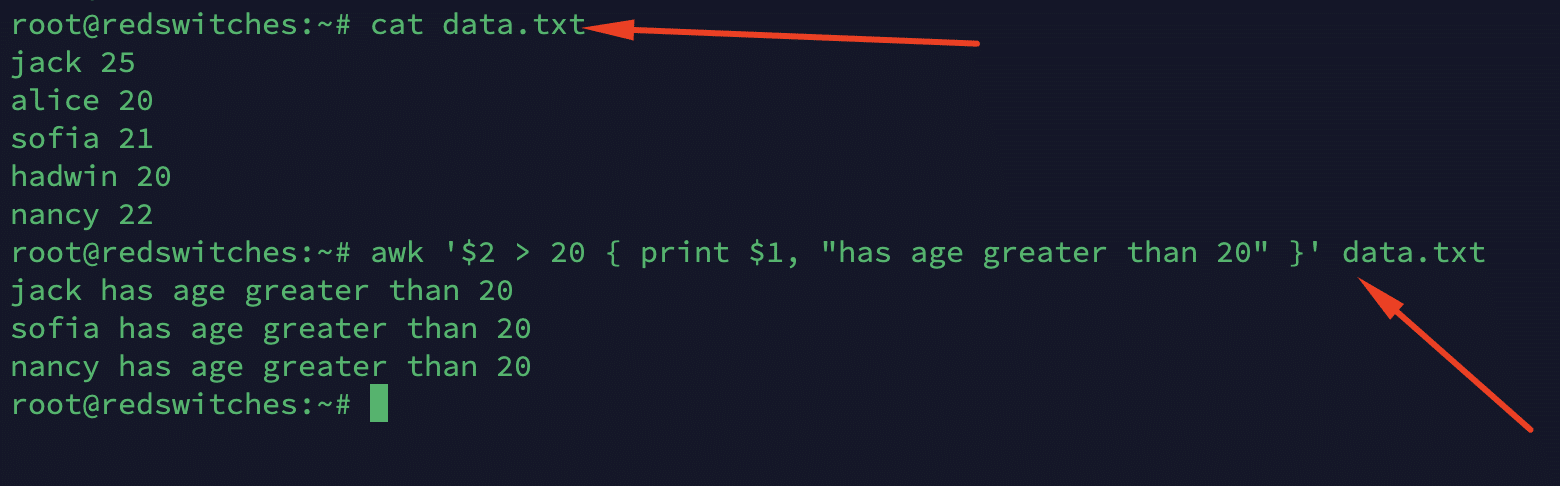
Consider a file named data.txt with the following content:
jack 25
alice 20
sofia 21
hadwin 20
nancy 22
The following command prints the names of individuals whose age (second field) exceeds 20.
# awk '$2 > 20 { print $1, "has age greater than 20" }' data.txt
String Comparison
awk supports traditional relational operators like <, >, ==, !=, etc.
Consider the following command that prints a message when the first field is exactly equal to banana in the example.txt file:
# awk '$1 == "banana" { print "Found banana!" }' example.txt

Range Patterns
These patterns are used to specify a range of lines using two patterns separated by a comma. Consider the following example that prints the names of individuals aged between 10 and 30.
# awk '$2 >= 10 && $2 <= 30 { print $1, "has age between 10 and 30" }' data.txt

Compound Patterns
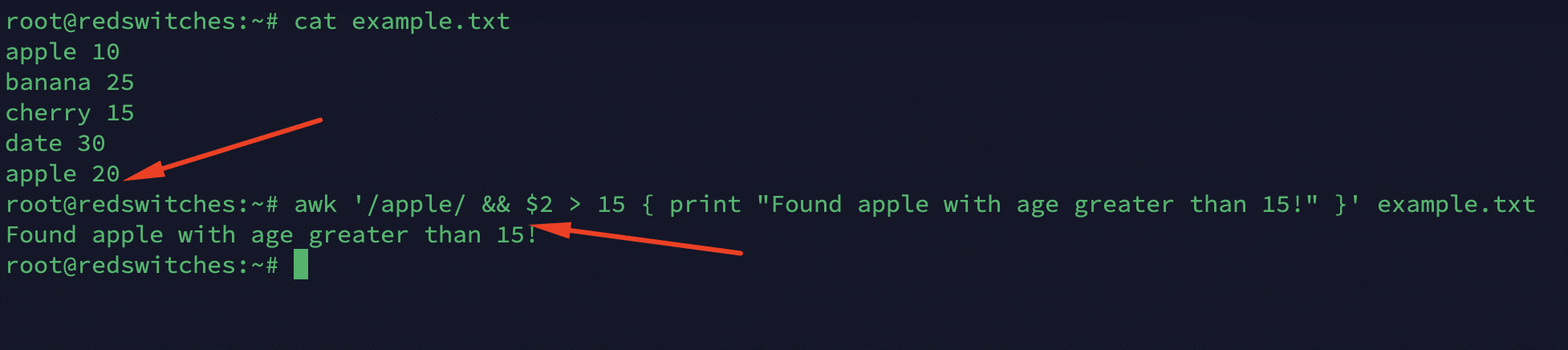
You can use logical operators && (and), || (or), and ! (not) to combine patterns. For instance, the following command contains a pattern that prints a message when apple is found in the first field and the age (the second field) exceeds 15.
# awk '/apple/ && $2 > 15 { print "Found apple with age greater than 15!" }' example.txt
Special Patterns
You can use BEGIN and END as special pattern blocks.
BEGIN is executed before any input is read. You can use it for initialization and setting pre-pattern-parsing conditions.
END is executed after all input has been processed. This is often used for the final summary/presentation and post-execution cleanup.
For instance, this command uses the BEGIN and END special characters or patterns to print messages before and after data processing
# awk 'BEGIN { print "Processing started..." } { print $1 } END { print "Processing completed." }' data.txt

Similarly, BEGINFILE and ENDFILE (available in the GNU AWK extension) special pattern blocks for actions performed at the start and end of each processed file.
Empty Pattern
An empty pattern is a special condition where an awk command does contain a pattern. In this case, the command matches all records. For instance, the following command prints every line of the input:
# { print $0 }
Similarly, the following command applies the action to every line in the file since there is no specific pattern:
# awk '{ print "This line will be processed for every record." }' data.txt

The awk Actions
An action in awk is a set of commands executed when the input record (typically a line of the file or input stream) matches the specified pattern.
Pattern-action pairs serve as the rules at the core of awk operations. The action is executed for every input record if no pattern is given.
Actions in awk are enclosed in curly braces { } and can consist of various statements, like assignments, function calls, conditionals, loops, and print statements.
The Basic awk Action Structure
The basic structure of an awk pattern-action command is:
pattern { action }
When executed, if the current record pattern matches, the action is executed.
Types of Action Statements
Print Statements
The most common action in awk scripts is the print statement, which outputs data. The following command illustrates the print statement and prints the first field of every record:
# { print $1 }
Variable Assignments
You can assign values to variables for processing within an awk script. For instance, the following command adds the value of the second field to the sum variable:
# { sum += $2 }
Conditional Statements
You can use the standard conditional operators (If, else, else if) to execute actions based on the outcome of specific conditions. For instance, the following command prints the first field if it’s greater than 100:
# { if ($1 > 100) print $1 }
Loop Statements
awk supports for, while, and do while loop statements for iterative operations. For instance, the following statement sums all fields in a record:
# { for (i = 1; i <= NF; i++) sum += $i }
Arrays
AWK supports associative arrays for more complex data manipulation.
For instance, the following statement keeps a count of occurrences of each value in the first field:
# { count[$1]++ }
Built-in Functions
AWK has several built-in string functions, arithmetic, and time manipulation. For instance, this command prints the first 5 characters of the first field:
# { print substr($1, 1, 5) }
User-defined Functions
You can define custom functions in awk statements for reusable code blocks. Here’s an example of a user-defined custom function:
# function printColumn(column) { print $column }
Output Redirection
In the absence of any specific mention, awk defaults to the stdout. However, you can use pipes or redirection to change this default. For instance, the following command redirects the print output to a file:
# { print $1 > “output.txt” }
Read more about awk utility in our comprehensive coverage of the command usage and application in text processing.
Also Read: lsof Command in Linux with Examples
Also Read: Mastering the Linux tee Command for Redirecting Output In 9 Examples
Conclusion
The awk command has proven to be a powerful and versatile tool for text processing and data extraction in Unix-like operating systems. Through a combination of patterns and actions, awk allows users to perform a wide range of tasks, from essential text extraction and filtering to more advanced operations like calculations and pattern matching. We showcased the flexibility and efficiency of awk in handling various text-processing scenarios.
RedSwitches would be happy to help you find the best server solutions for moving your business ahead. We offer the best dedicated server pricing and deliver instant dedicated servers, usually on the same day the order gets approved.
Whether you need a dedicated server, a traffic-friendly 10Gbps dedicated server, or a powerful bare metal server, we are your trusted hosting partner.
Contact us now, and let’s start your company’s technological advancement together.
Q. What is awk, and how is it used in Linux and Unix?
awk is a scripting language used for text processing and manipulation in Linux and Unix. It is used to search and manipulate text and is particularly useful for processing structured data, such as tables. It can be used as a standalone command or within a script.
Q. What is the basic syntax of an awk command in Linux and Unix?
The basic syntax of an awk command in Linux and Unix is: awk ‘pattern { action }’ filename Where ‘pattern’ specifies the search pattern, ‘action’ specifies the command to be executed when the pattern is found, and ‘filename’ is the name of the file to be processed.
Q. How can I use awk to process text in Linux?
You can use awk to process text in Linux by searching for specific patterns or conditions in a file and then performing actions based on those patterns or conditions. For example, you can use awk to extract specific fields from a file, calculate totals, or format data in a specific way.
Q. What are the core features of the awk command in Linux and Unix?
The features of an awk command in Linux and Unix include powerful text processing capabilities, the ability to work with regular expressions for pattern matching, support for variables and control statements, and the option to specify the input and output field separator, among others. awk is a versatile tool for manipulating text data.
Q. How do I get started with awk in Linux and Unix?
You can begin by learning the basic syntax and common usage patterns of awk commands. You can find numerous tutorials and examples online to understand how to use awk for text processing and manipulation.
Q. What are the different ways to use the awk command in Linux and Unix?
You can use the awk command in Linux and Unix by executing it directly in the terminal to process text data from standard input or files. Additionally, you can create awk scripts in separate files and execute them using the command line with the -f option to specify the script file.
Q. How does the awk command handle field and record separators in Linux and Unix?
awk command in Linux and Unix uses the field separator (FS) and record separator (RS) to handle how input data is parsed and processed. The field separator determines how fields are separated within each record, while the record separator specifies how records are separated from each other.
Q. What types of variables can be used in awk command in Linux and Unix?
In an awk command in Linux and Unix, variables such as strings, numbers, arrays, and special built-in variables can be used to store and manipulate data. You can use these variables to perform calculations, store intermediate results, and control the behavior of AWK commands.
Q. Can you provide examples of using the awk command for text processing in Linux and Unix?
Sure, some examples of using the awk command for text processing in Linux and Unix include extracting specific columns from a CSV file, searching for patterns in log files, calculating totals or averages from numerical data, and reformatting text files based on specific criteria.
