
Businesses rely heavily on servers and infrastructure to keep applications connected and running smoothly. Visitors expect these applications to work anytime and every time they access them.
However, unexpected power outages and planned maintenance of critical application components and underlying hardware equipment can disrupt users’ access. This downtime decreases the quality of the user experience and results in adverse customer reactions and loss of reputation.
Fault tolerance (FT) and High Availability (HA) are two main ways to ensure critical applications and infrastructure availability to minimize interruptions due to errors, failures, and unexpected errors. Utilizing either of these choices will help you minimize (or even eliminate) connectivity issues for the inter-connected system components.
The debate around Fault tolerance vs High availability has attained more significance today when SaaS has become the dominant way to deliver software to customers.
Let’s start with the definition of redundancy and then go into the details of Fault Tolerant and High Availability paradigms.
Table Of Content
- What is Redundancy?
- What is Fault Tolerance?
- Advantages of Fault Tolerance
- Disadvantages of Fault Tolerance
- What is High Availability?
- Advantages of High Availability
- Disadvantages of High Availability
- Why Are Fault Tolerance and High Availability Important?
- Best Practices to Configure Fault Tolerance and High Availability
- Conclusion
- FAQs
What is Redundancy?
Redundancy refers to having two (or more) servers with duplicate or mirrored data. Fault tolerance helps ensure that the core business operations stay connected and available online, whereas redundancy concerns the duplication of hardware and software resources. On the other hand, high availability offers automatic failover in case of a failure, whereas redundancy involves minimizing points of hardware or software failures.
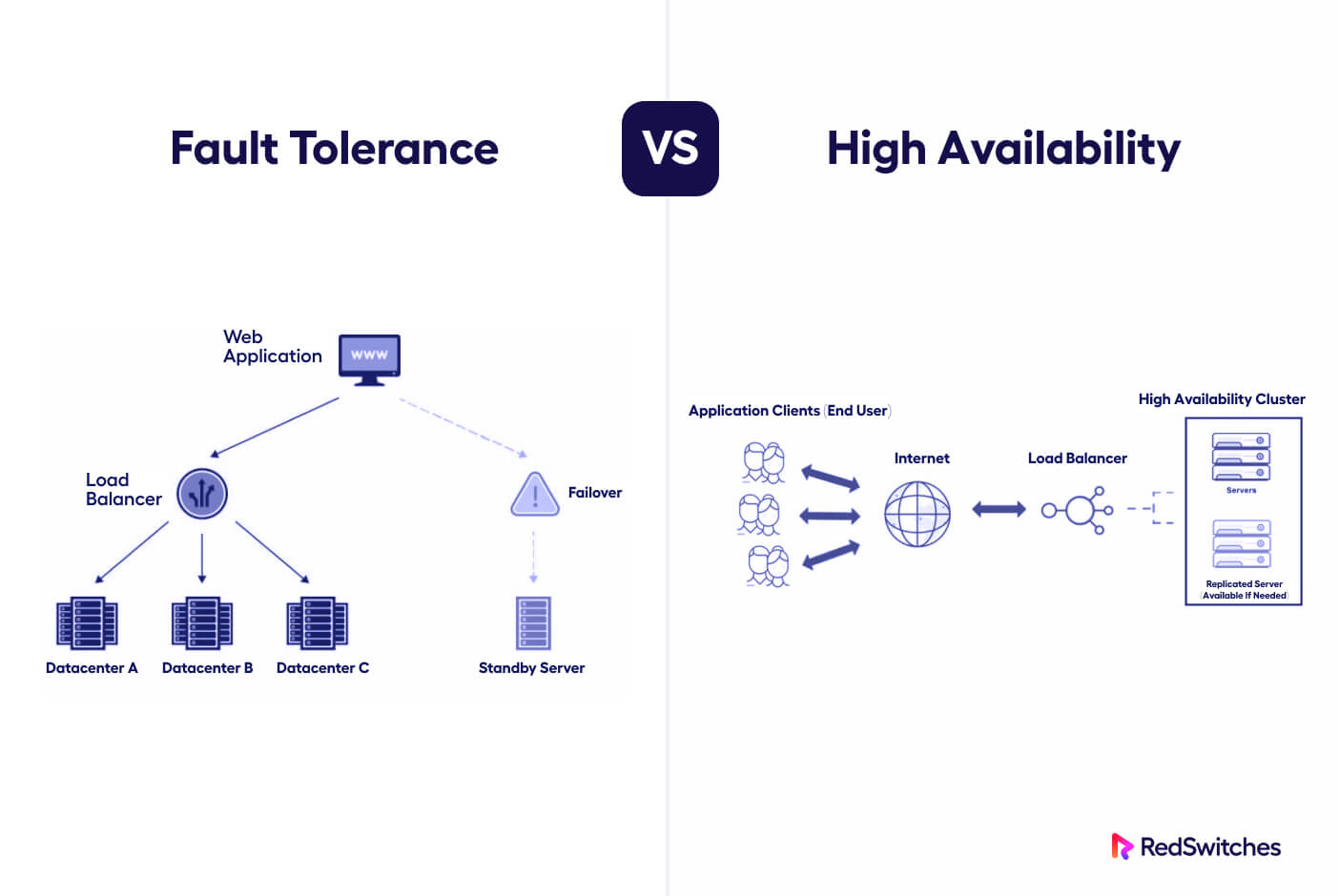
What is Fault Tolerance?
Fault tolerance is a form of redundancy that ensures visitors can access and utilize the system, even when one or more components, like the CPU or a single server, become unavailable for any reason.
In the fault tolerance vs high availability debate, fault tolerance allows users to use the application or view the webpages with limited functionality. Unlike high-availability systems, fault-tolerant systems don’t aim to keep all systems up and running with automatic failovers to other working nodes/components of the system.
Fault-tolerant systems are designed to withstand almost any type of failure since there is no crossover event. Instead, several redundant components store copies of user requests and changes to data. As a result, if a component fails, the others can pick up the slack. This makes fault-tolerant/backup systems the perfect solution for mission-critical applications that cannot allow or afford downtime.
A good example of a fault-tolerant system is a storage area network (SAN). A SAN is a scalable central network storage cluster for critical data that is fault-tolerant, thanks to low latency ethernet connections directly to the servers in the cluster. With a SAN, users can transfer data sequentially or in parallel without affecting the host server’s performance.
Advantages of Fault Tolerance
Now that you know about the idea of fault tolerance, we will look at the benefits of this idea. The list includes:
Zero Interruption
The main distinction between high availability and fault tolerance is that fault tolerance provides zero service interruption. This means end-users can rely on the system to be up and running at all times. The provider can deliver essential services without interruptions, such as:
- Hardware upgrade or replacement.
- Software patches.
- Data migrations.
- Backups
A fault-tolerant system is designed to continue operating even during a component failure. A backup component automatically takes over if a component fails, so there is no downtime or data loss. This is an important point in the debate of high availability vs fault tolerance because a highly available system is designed to prevent component failures from happening in the first place.
No Loss of Data
Fault-tolerant systems generally have lower data loss incidents because there is no component crossover. As a result, the system continues to accept, process, and write data during an incident.
Disadvantages of Fault Tolerance
The idea of Fault Tolerance systems does have some disadvantages, such as:
Complex System Implementation
By design, fault-tolerant systems have a complex design to manage users’ requests and traffic volume while duplicating information. It takes time and considerable effort to mirror information (and resources) from both hardware and software standpoints. As a result, designers often need to build subsystems to handle data and request mirroring and serve responses to the end-users.
In practical terms, this means parallel processing of user requests within a fault-tolerant environment. Unfortunately, this complicated multi-node design has more opportunities for design failures that can eventually bring down the entire system.
This complexity is an important factor in the Fault Tolerance vs High-Availability decision process.
Higher Costs
When it comes to cost, businesses must weigh the pros and cons of investing in a fault-tolerant system. While such systems have many advantages (such as providing security and connectivity during unexpected issues), they also come with higher setup and maintenance costs. In addition, hardware and software component requirements can get expensive, and you need to hire additional team members for system management.
So, when deciding whether to invest in a fault-tolerant system, businesses must decide if the benefits are worth the costs. Alternatively, if a few microseconds of connectivity issues during a crossover in a High Availability system is not a major issue, perhaps the business can do without the higher costs of a fault-tolerant setup.
What is High Availability?
High availability systems are created to have extended uptime by eliminating all possible points of failure that could cause mission-critical applications or websites to go offline during unfortunate events, such as increased traffic, malicious attacks, or hardware malfunction.
In simple words, redundancy is crucial in achieving high availability – you need one to have the other. This is achieved by implementing various levels of replication and failover capabilities into an infrastructure so that if one component fails, another can immediately step in and take its place without any user-facing downtime.
The most interesting aspect of a high availability system is how a backup takes over automatically if a component fails. The process is software-based and uses a monitoring component (load balancer) to identify failures and initiate a transfer of traffic or resources from primary servers to backup servers or machines. This ensures your services are always available and running smoothly.
Advantages of High Availability
Now that we have learned about High Availability, it’s time to discuss the advantages of the approach and the factors that play an important role in deciding high availability vs fault tolerance.
Cost Savings
The main advantage of high availability systems is that they are easier to design and implement. As a result, they cost less than fault-tolerant designs. High availability systems are simpler, which makes them easier to use and maintain.
Easily Scalable
Highly available solutions are also easily scalable – excellent news for infrastructure designers! The simplest way to introduce a highly available system is to use duplicate infrastructure, meaning the system’s capabilities can be increased without much investment in design. This speeds up the scaling of the system without requiring much time and resources.
Simple Load-Balancing Solutions
Highly available systems are a great way to provide load-balancing without adding extra infrastructure. In this setup, traffic is split between multiple environments, which helps distribute the workload and manage traffic and requests in the event of a failure.
For example, half of your website traffic can go to server A while the other half goes to server B. This split reduces the load on each server or node and results in a smoother user experience.
In case of a node failure, the monitoring component detects the failure event, and the traffic and requests coming to the failing server are diverted to redundant servers. End-users often don’t feel any difference at the front end when this happens.
Disadvantages of High Availability
In the fault tolerance vs high availability debate, you’ll find that the following pointers are quoted as the disadvantages of the HA systems.
Service Hiccups
A crossover event in a high availability system is when traffic is moved or redirected from failing systems to ones still operational. This process involves several factors, such as:
- The software monitoring component that determines if there is a failure
- Differentiating between failures and false positives (for example, when there is just heavy traffic or a lost packet)
- The event that alerts the need to crossover to a healthy system
Even though the process is fast, users may experience a brief outage (no more than a few seconds) while the crossover occurs. However, this outage is much shorter (and less noticeable) than a complete interruption in service that would happen if there was no crossover event.
Required Component Duplication
High-availability software systems are generally built by duplicating the components to protect against outages and hardware failures.
Resource duplication has a cost, but it is generally lower than the potential revenue loss resulting from hours-long service outages.
The cost of duplication is like insurance: You regularly pay for the “just in case” event.
Data Loss (Rare)
The most detrimental factor during a service disruption is not the interruption of service but potential data loss. The system often resends users’ requests to secondary components in the changeover event. However, in systems with a very high data movement rate, there is a chance of loss during the changeover event.
Why Are Fault Tolerance and High Availability Important?
Fault tolerance and high availability are critical for ensuring reliable operations and service delivery.
Fault tolerance is the ability of a system to continue operating during component failure or other unexpected events. At the same time, high availability is the ability of a system to provide timely access to data and services with minimal disruption.
Both ideas are vital for guaranteeing the reliability and performance of any system. However, both ideas are significantly different in implementation. Infrastructure designers can combine these ideas to implement a system that provides a comprehensive strategy for ensuring reliable system operations.
The benefits of building fault tolerance and high availability in system design are clear. Adopting a strategy that employs both approaches can significantly reduce service outages, minimize data loss, and improve customer satisfaction by providing reliable access to data and services.
Additionally, this combined strategy helps reduce the impact of downtime due to component failure and the cumulative costs of repairing, replacing, or upgrading failing components. The implementation also helps optimize system performance by ensuring that resources are always available and ready to use.
Best Practices to Configure Fault Tolerance and High Availability
Organizations should consider fault tolerance and high availability as essential ingredients of system architecture.
While designing the architecture, the ICT teams should understand that while these concepts are related, they are distinct in implementation and should be treated as such in systems design.
The most critical aspect of this implementation is to mix and match these ideas to maximize reliability and performance. For instance, organizations should consider using redundant components, such as power supplies or storage systems, to increase fault tolerance.
While at the drawing board, the designers should consider setting up testing and monitoring subsystems to track performance and highlight (and address) problems before the system slows down and the issues become roadblocks.
Scalability is another critical aspect of systems architecture. Organizations should include future growth forecasts when designing the system architecture. Usually, this involves adding new components or upgrading the existing ones. Additionally, allowing for network redundancy, such as multiple networks or multiple connections between locations, is essential to increase fault tolerance and improve performance. Organizations should consider virtualization options to increase availability and scalability.
Conclusion
Fault tolerance vs high availability is an ongoing discussion in systems architecture and service delivery. Both approaches are used to build systems that increase the reliability and availability of systems, scripts, and applications.
When it comes to hosting solutions like dedicated servers, 10 Gbps dedicated servers, instant dedicated servers, and bare metal servers , understanding these concepts becomes crucial.
Fault tolerance focuses on the ability of a system to continue functioning normally in the event of component failure. In contrast, high availability focuses on the ability of a server to remain available and accessible to users with minimal downtime.
At RedSwitches, we consider both essential aspects of a comprehensive service delivery and data protection strategy. We help our clients build systems that come with regular backups and disaster recovery plans to protect data and ensure sustained service delivery during a failure.
If you’re looking for a robust server infrastructure, we offer the best dedicated server pricing and deliver instant dedicated servers, usually on the same day the order gets approved. Whether you need a dedicated server, a traffic-friendly 10Gbps dedicated server, or a powerful bare metal server, we are your trusted hosting partner.
FAQs
Q: What is Fault Tolerance?
Fault Tolerant computer systems aim to maintain business continuity and high availability. As a result, fault tolerance solutions frequently concentrate on sustained operations of mission-critical systems and applications.
Q: What is the difference between high availability and fault tolerance?
A: High availability refers to the ability of a system to remain operational without any downtime, even in the event of certain failures. Fault tolerance, on the other hand, refers to the ability of a system to continue functioning with minimal or no disruption in the event of a failure or fault. While both concepts aim to ensure continuous system operation, fault tolerance typically involves more robust mechanisms and redundancy.
Q: How does high availability compare to disaster recovery?
A: High availability focuses on minimizing system downtime and ensuring continuous operation, while disaster recovery focuses on recovering from catastrophic events, such as natural disasters or major system failures. High availability aims to prevent downtime altogether, while disaster recovery plans for the worst-case scenarios and focuses on quickly recovering the system after a major disruption.
Q: What are the key differences between high availability and fault tolerance in AWS?
A: In AWS, high availability refers to designing and implementing systems that can automatically recover from failures and provide seamless operation. Fault tolerance, on the other hand, involves building redundancy and resiliency into the system architecture to mitigate the impact of failures. In essence, high availability focuses on minimizing downtime, while fault tolerance enhances the system’s ability to withstand failures.
Q: Can you explain the concept of availability zones in AWS?
A: In AWS, availability zones are distinct locations within a region that are engineered to be isolated from failures in other availability zones. Each availability zone comprises redundant power, networking, and cooling to ensure high availability and fault tolerance. By deploying resources across multiple availability zones, you can achieve greater resilience and protect your applications from single points of failure.
Q: How does fault tolerance in AWS differ from fault-tolerant systems?
A: Fault tolerance in AWS refers to building redundancy and resiliency into your cloud infrastructure using AWS services and features such as multiple availability zones, elastic load balancing, and auto scaling. Fault-tolerant systems, on the other hand, are designed to tolerate and recover from hardware or software failures using techniques like data replication, failover mechanisms, and redundant components.
Q: What is the role of backups in achieving high availability and fault tolerance?
A: Backups play a crucial role in achieving high availability and fault tolerance by providing a means to restore data in the event of failures or disasters. Regularly backing up your critical data ensures that you can recover the system to a known state and minimize the impact of data loss. Backups can be stored in different locations for added redundancy and to meet business continuity requirements.
Q: How does the load balancer contribute to achieving high availability?
A: Load balancers distribute incoming traffic across multiple instances or servers, ensuring that the load is evenly distributed and no single instance is overwhelmed. By distributing the workload, load balancers improve system performance, prevent server overload, and automatically route traffic away from unhealthy instances. This helps to achieve high availability by minimizing the risk of single points of failure.
Q: What does it mean for a system to be highly available?
A: A highly available system is one that is designed and configured to ensure continuous operation with minimal downtime or disruption. It often involves redundancy, load balancing, fault tolerance mechanisms, and careful architecture design to eliminate single points of failure and to ensure that the system can continue running even when individual components or resources fail.
Q: How does high availability differ from fault tolerance and disaster recovery?
A: High availability focuses on minimizing downtime and ensuring continuous operation, while fault tolerance aims to build redundancy and resiliency into the system architecture. Disaster recovery, on the other hand, is concerned with planning and implementing strategies to quickly recover from major disruptions or catastrophic events. While all three concepts are related, they have different objectives and approaches to ensuring system continuity.
Q: What is an availability zone in AWS?
A: An availability zone is a physically separate data center within an AWS region. Each availability zone is designed to be isolated from failures in other availability zones, providing a higher level of resilience and availability.
Q: What is an EC2 instance in AWS?
A: An EC2 instance is a virtual server in the Amazon Elastic Compute Cloud (EC2) service. It allows you to quickly and easily scale compute resources in the cloud and is a key component in building highly available and fault-tolerant systems on AWS.
Q: What is a load balancer in the context of high availability and fault tolerance?
A: A load balancer is a component that evenly distributes incoming network traffic across multiple servers or instances. It helps to increase the availability and fault tolerance of a system by directing traffic to healthy servers and reducing the load on any single server.
Q: What is a single point of failure?
A: A single point of failure is a component within a system that, if it fails, would cause the entire system to fail. In highly available and fault-tolerant systems, the goal is to eliminate single points of failure by introducing redundancy and failover mechanisms.
Q: What is a disaster recovery strategy?
A: A disaster recovery strategy is a documented plan that outlines how an organization will respond to and recover from a catastrophic event. It includes steps for restoring operations, recovering data, and minimizing downtime.
